Now vibe coding, so learning hammer FE ?
《让React Compiler接管Memoization后,我踩了哪些坑》
标签:#前端 #React #ReactCompiler #Memoization #NextJS #ReactHookForm
总结:
作者在生产级Next.js项目中启用React Compiler v1.0的真实踩坑记录。编译器确实能自动处理大部分memoization,但"大部分"这个词背后藏着不少陷阱:React Hook Form的
文章要点:
1. React Compiler的本质是Babel插件:它通过为每个组件预分配扁平缓存数组(内部hook
2. React Hook Form的
3. 有些
4. DevTools的Memo徽章会误导你:徽章只表示编译器"处理过"该组件,不代表优化成功。即使组件违反React规则(如直接修改props),徽章依然可能出现,真正没徽章的只有显式加了
5. 迁移有明确的正确顺序:先升级eslint-plugin-react-hooks到v7+并修复lint错误,再在feature分支启用编译器,最后用Profiler和E2E测试验证,不要依赖Memo徽章作为正确性信号
URL:https://blog.logrocket.com/react-compiler-memoization-what-actually-broke/
标签:#前端 #React #ReactCompiler #Memoization #NextJS #ReactHookForm
总结:
作者在生产级Next.js项目中启用React Compiler v1.0的真实踩坑记录。编译器确实能自动处理大部分memoization,但"大部分"这个词背后藏着不少陷阱:React Hook Form的
watch()因内部可变状态导致实时预览冻结;Chart.js的点击处理器在移除useCallback后出现数据过时问题;DevTools的Memo徽章仅表示组件被"处理"而非"成功优化"。核心结论是:迁移不是一键操作,需要先升级eslint-plugin-react-hooks、在feature分支启用、用E2E测试覆盖,并保留那些跨越React边界的显式hook。文章要点:
1. React Compiler的本质是Babel插件:它通过为每个组件预分配扁平缓存数组(内部hook
_c)来实现比手写useMemo更细粒度的自动memoization,让你可以删掉大部分显式hook2. React Hook Form的
watch()直接翻车:启用编译器后,表单的实时预览完全冻结,原因是RHF依赖内部可变状态,编译器无法安全memoize。解决方案是用"use no memo"指令包裹useForm的调用3. 有些
useCallback真的删不得:Chart.js的点击处理器在移除useCallback后,高并发下偶尔引用旧数据。这不是编译器bug,而是编译器的memoization节奏与外部库(按引用注册回调)的预期不一致,最终选择保留useCallback并加注释说明4. DevTools的Memo徽章会误导你:徽章只表示编译器"处理过"该组件,不代表优化成功。即使组件违反React规则(如直接修改props),徽章依然可能出现,真正没徽章的只有显式加了
"use no memo"的组件5. 迁移有明确的正确顺序:先升级eslint-plugin-react-hooks到v7+并修复lint错误,再在feature分支启用编译器,最后用Profiler和E2E测试验证,不要依赖Memo徽章作为正确性信号
URL:https://blog.logrocket.com/react-compiler-memoization-what-actually-broke/

《水合不匹配的隐藏代价:一个错误如何让LCP从绿变红》
标签:#前端 #React #HydrationMismatch #LCP #CoreWebVitals #SSR
总结:
文章揭示了React SSR中一个被严重低估的性能杀手:单个水合不匹配(Hydration Mismatch)就能让LCP从绿色直接跌到红色。核心逻辑由三个事实拼接而成——水合不匹配会触发整个DOM重新挂载;使用
文章要点:
1. 水合不匹配会强制重挂载整个DOM:当服务端和客户端渲染结果不一致时,React不会局部修补,而是找到最近的
2. 字体加载导致文本膨胀是正常现象:使用
3. LCP只关心"新元素":浏览器记录LCP候选者时,仅在新元素加入DOM时重新评估;已有元素单纯尺寸变化不会触发更新,这是设计上的关键细节
4. 三者叠加就是灾难:文本先因字体加载膨胀,再因水合不匹配被删除并重新插入DOM,浏览器将其识别为"更大的新元素",LCP时间瞬间跳到水合完成时刻
5. 修复方案很直接:优先避免水合不匹配;如果实在无法避免,将不匹配元素包裹在
URL:https://3perf.com/blog/hydration-mismatch/
标签:#前端 #React #HydrationMismatch #LCP #CoreWebVitals #SSR
总结:
文章揭示了React SSR中一个被严重低估的性能杀手:单个水合不匹配(Hydration Mismatch)就能让LCP从绿色直接跌到红色。核心逻辑由三个事实拼接而成——水合不匹配会触发整个DOM重新挂载;使用
font-display: swap时,Web字体加载后文本会膨胀;而LCP只测量新加入DOM的元素,忽略已有元素的尺寸变化。三者叠加后,字体加载后的文本膨胀本应不影响LCP,但DOM重挂载让浏览器将其视为"新元素",导致LCP时间被记录到水合完成时(通常5秒以上),严重拖垮核心指标。文章要点:
1. 水合不匹配会强制重挂载整个DOM:当服务端和客户端渲染结果不一致时,React不会局部修补,而是找到最近的
Suspense边界并重新挂载整个子树;没有边界时整页重挂2. 字体加载导致文本膨胀是正常现象:使用
font-display: swap时,系统字体切换到Web字体的过程中,相同字符的物理尺寸往往不同,文本会轻微变大或变小3. LCP只关心"新元素":浏览器记录LCP候选者时,仅在新元素加入DOM时重新评估;已有元素单纯尺寸变化不会触发更新,这是设计上的关键细节
4. 三者叠加就是灾难:文本先因字体加载膨胀,再因水合不匹配被删除并重新插入DOM,浏览器将其识别为"更大的新元素",LCP时间瞬间跳到水合完成时刻
5. 修复方案很直接:优先避免水合不匹配;如果实在无法避免,将不匹配元素包裹在
Suspense边界内,限制重挂载范围,防止LCP候选元素被波及URL:https://3perf.com/blog/hydration-mismatch/
《一次被低估的重构如何让内存暴降90%——TanStack_Table_V9内存优化揭秘》
标签:#前端 #TanStackTable #性能优化 #JavaScript #内存管理
总结:
TanStack_Table_V9通过将行、列、单元格和表头对象的方法从实例属性迁移到共享原型上,实现了大型表格场景下最高达90%的内存节省。这一改动让V9能处理1000-1600万行数据(V8仅约150万行即达4GB内存上限),同时保持了动态特性组合的能力,仅带来解构方法调用这一处Breaking_Change。
文章要点:
1. 数据亮眼:处理100万行×8列时,V9比V8节省超2.4GB内存,最高降幅达90.5%,表格承载能力从约150万行跃升至1000-1600万行
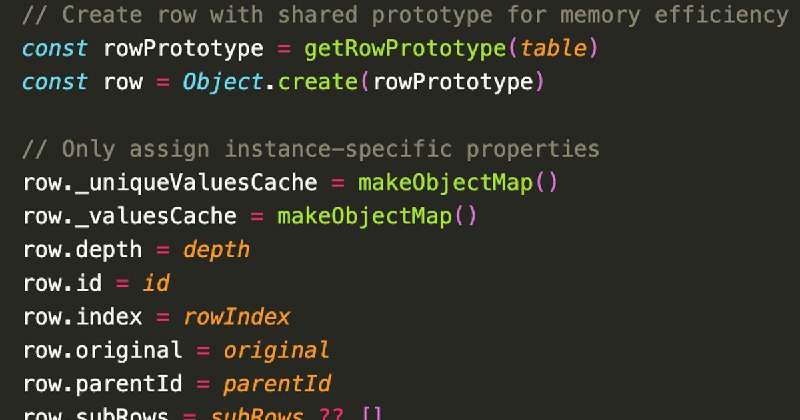
2. 核心手法:用
3. 不用类的智慧:因为TanStack_Table的特性是动态组合的(按需注册排序、筛选、分页等),单继承的Class难以优雅表达"条件式多重继承",手动原型模式更灵活
4. 唯一代价:方法不能再解构调用(如
5. 通用启示:任何需要大规模创建相似对象的库或应用,都可以借鉴这种"共享原型+实例数据分离"的模式来优化内存
URL:https://tanstack.com/blog/tanstack-table-v9-memory-performance
标签:#前端 #TanStackTable #性能优化 #JavaScript #内存管理
总结:
TanStack_Table_V9通过将行、列、单元格和表头对象的方法从实例属性迁移到共享原型上,实现了大型表格场景下最高达90%的内存节省。这一改动让V9能处理1000-1600万行数据(V8仅约150万行即达4GB内存上限),同时保持了动态特性组合的能力,仅带来解构方法调用这一处Breaking_Change。
文章要点:
1. 数据亮眼:处理100万行×8列时,V9比V8节省超2.4GB内存,最高降幅达90.5%,表格承载能力从约150万行跃升至1000-1600万行
2. 核心手法:用
Object.create创建共享原型对象,将方法统一挂载到原型上,实例只保留独有数据,彻底消灭百万级重复函数对象及其闭包作用域3. 不用类的智慧:因为TanStack_Table的特性是动态组合的(按需注册排序、筛选、分页等),单继承的Class难以优雅表达"条件式多重继承",手动原型模式更灵活
4. 唯一代价:方法不能再解构调用(如
const {getValue} = row会丢失this),且Object.keys/{...row}浅拷贝不会包含方法,但直接调用row.getValue()一切正常5. 通用启示:任何需要大规模创建相似对象的库或应用,都可以借鉴这种"共享原型+实例数据分离"的模式来优化内存
URL:https://tanstack.com/blog/tanstack-table-v9-memory-performance
《MDN 推出官方 MCP 服务器,让 AI 助手实时获取权威 Web 文档》
标签:#前端 #AI工具 #MCP #MDN #浏览器兼容性 #VSCode #Claude
总结:
MDN 官方发布了一款实验性 MCP(Model Context Protocol)服务器,旨在让 LLM 和编程助手直接访问 MDN 的搜索、文档及浏览器兼容性数据(BCD),解决 AI 回答中可能出现的过时或错误信息问题。开发者可通过远程服务或本地部署方式接入,支持 VS Code、Claude Code 等 MCP 兼容客户端,实现编码时一键查询 API 用法和兼容性,无需离开编辑器。
文章要点:
1. 官方出品,权威数据源:这是 MDN 官方推出的 MCP 服务器,直接对接 MDN 的搜索 API、文档 JSON API 以及浏览器兼容性数据(BCD),确保 AI 获取的是最新、最准确的 Web 平台技术资料,而不是训练数据中的"旧知识"
2. 六大核心工具,覆盖开发全场景:提供
3. 远程 + 本地双模式部署:既可以一键接入官方远程服务(
4. 无缝集成主流开发工具:完美支持 VS Code、Claude Code、Cursor 等 MCP 兼容客户端,配置简单,安装后直接在 AI 聊天中调用工具,真正实现"边写代码边查文档"的流畅体验
5. 实验性质,持续迭代中:目前处于实验阶段,Mozilla 会收集查询数据以优化服务(可 opt-out),且保留随时调整或下线服务的权利,建议开发者关注官方动态
URL:
https://developer.mozilla.org/en-US/blog/introducing-mdn-mcp-server/
标签:#前端 #AI工具 #MCP #MDN #浏览器兼容性 #VSCode #Claude
总结:
MDN 官方发布了一款实验性 MCP(Model Context Protocol)服务器,旨在让 LLM 和编程助手直接访问 MDN 的搜索、文档及浏览器兼容性数据(BCD),解决 AI 回答中可能出现的过时或错误信息问题。开发者可通过远程服务或本地部署方式接入,支持 VS Code、Claude Code 等 MCP 兼容客户端,实现编码时一键查询 API 用法和兼容性,无需离开编辑器。
文章要点:
1. 官方出品,权威数据源:这是 MDN 官方推出的 MCP 服务器,直接对接 MDN 的搜索 API、文档 JSON API 以及浏览器兼容性数据(BCD),确保 AI 获取的是最新、最准确的 Web 平台技术资料,而不是训练数据中的"旧知识"
2. 六大核心工具,覆盖开发全场景:提供
mdn_search(关键词搜索)、mdn_doc(获取完整文档)、mdn_compat(浏览器兼容性检查)、mdn_list(浏览 BCD 特性)、mdn_css(CSS 属性定义)、mdn_http(HTTP 参考)等工具,从查文档到看兼容性一站搞定3. 远程 + 本地双模式部署:既可以一键接入官方远程服务(
https://mcp.mdn.mozilla.net/),也可以克隆仓库本地运行,满足对数据隐私有顾虑的团队需求;本地模式支持 MCP Inspector 调试,开发体验友好4. 无缝集成主流开发工具:完美支持 VS Code、Claude Code、Cursor 等 MCP 兼容客户端,配置简单,安装后直接在 AI 聊天中调用工具,真正实现"边写代码边查文档"的流畅体验
5. 实验性质,持续迭代中:目前处于实验阶段,Mozilla 会收集查询数据以优化服务(可 opt-out),且保留随时调整或下线服务的权利,建议开发者关注官方动态
URL:
https://developer.mozilla.org/en-US/blog/introducing-mdn-mcp-server/
《TanStack Start 心智模型:给 Next.js 开发者的迁移指南》
标签:#前端 #TanStack_Start #Next.js #React_Router #TypeScript #全栈框架
总结:
文章从一位资深 Next.js 开发者的视角,系统对比了 TanStack Start 与 Next.js App Router 的核心差异。核心心智模型翻转在于:Next.js 默认服务端优先、隐式约定驱动;TanStack Start 默认同构 React、显式声明边界。作者逐一对比了路由类型系统、数据获取、服务端函数、缓存策略、渲染模式、认证防护等关键维度,指出 TanStack Start 更适合高交互 SaaS 类应用,而 Next.js 在内容型站点和成熟生态上仍有优势。
文章要点:
1. 心智模型大翻转:Next.js 默认组件跑在服务端,需要显式标注
2. 路由类型系统碾压:Next.js 的文件路由是约定驱动,TypeScript 对参数无能为力;TanStack Router 会在构建时自动生成完全类型化的路由树,路径参数、搜索参数、loader 返回值全部类型推断,拼写错误直接编译报错
3. 数据获取的"陷阱":Next.js 的 Server Component 只在服务端执行,天然安全;TanStack Start 的 loader 是同构的——SSR 时跑在服务端,客户端导航时跑在浏览器里,所以直接写数据库查询会泄露环境变量,必须用
4. 缓存哲学更简单:Next.js 历史上有复杂的四层缓存模型,v16 改为
5. 认证防护双层设计:
6. Remix 与 RSC 现状:TanStack Start 的 RSC 支持仍处于实验阶段,实现方式也与 Next.js 不同(更像客户端获取 Flight payload 后组装),如果生产环境重度依赖 RSC,Next.js 目前更成熟
7. 选型建议:内容型/营销站点选 Next.js;高交互 SaaS 后台、需要强类型安全、讨厌隐式缓存魔法的团队,TanStack Start 值得认真评估
URL:
https://www.adarsha.dev/blog/tanstack-mental-model-for-nextjs-developers
标签:#前端 #TanStack_Start #Next.js #React_Router #TypeScript #全栈框架
总结:
文章从一位资深 Next.js 开发者的视角,系统对比了 TanStack Start 与 Next.js App Router 的核心差异。核心心智模型翻转在于:Next.js 默认服务端优先、隐式约定驱动;TanStack Start 默认同构 React、显式声明边界。作者逐一对比了路由类型系统、数据获取、服务端函数、缓存策略、渲染模式、认证防护等关键维度,指出 TanStack Start 更适合高交互 SaaS 类应用,而 Next.js 在内容型站点和成熟生态上仍有优势。
文章要点:
1. 心智模型大翻转:Next.js 默认组件跑在服务端,需要显式标注
"use client" 才能上客户端;TanStack Start 默认组件同构(服务端+客户端都能跑),只有需要纯服务端逻辑时才用 createServerFn 显式声明,边界更清晰,不容易踩坑2. 路由类型系统碾压:Next.js 的文件路由是约定驱动,TypeScript 对参数无能为力;TanStack Router 会在构建时自动生成完全类型化的路由树,路径参数、搜索参数、loader 返回值全部类型推断,拼写错误直接编译报错
3. 数据获取的"陷阱":Next.js 的 Server Component 只在服务端执行,天然安全;TanStack Start 的 loader 是同构的——SSR 时跑在服务端,客户端导航时跑在浏览器里,所以直接写数据库查询会泄露环境变量,必须用
createServerFn 包裹4. 缓存哲学更简单:Next.js 历史上有复杂的四层缓存模型,v16 改为
'use cache' 显式 opt-in;TanStack Start 只有路由 loader 缓存 + 可选的 TanStack Query,没有隐式魔法,哪里缓存、哪里失效一目了然5. 认证防护双层设计:
beforeLoad 负责 UI 层面的重定向(用户体验),createServerFn 中间件负责数据层面的安全校验(真正的安全边界),两层职责分离,比 Next.js 把 edge middleware 和 action 内校验混在一起的方案更不容易遗漏6. Remix 与 RSC 现状:TanStack Start 的 RSC 支持仍处于实验阶段,实现方式也与 Next.js 不同(更像客户端获取 Flight payload 后组装),如果生产环境重度依赖 RSC,Next.js 目前更成熟
7. 选型建议:内容型/营销站点选 Next.js;高交互 SaaS 后台、需要强类型安全、讨厌隐式缓存魔法的团队,TanStack Start 值得认真评估
URL:
https://www.adarsha.dev/blog/tanstack-mental-model-for-nextjs-developers

《React Router v8 发布:最"无聊"的一次大版本升级》
标签:#前端 #React_Router #Remix #Vite #React19 #SPA_SSR #框架升级
总结:
React Router v8 正式发布,主打"最无聊的大版本升级"理念。v7 引入的 Framework Mode 已成熟,v8 在此基础上将多个 future flags 转正为默认行为,带来 40+ 项改进,包括中间件增强、路由模块拆分、类型安全的 href、Link 遮罩等。破坏性变更极少,升级路径平滑。团队同时宣布采用年度大版本发布节奏,并正式将 React Router v6 和 Remix v2 标记为生命周期结束(EOL)。
文章要点:
1. 升级超省心:v8 的破坏性变更极少,大部分改动在 v7 中就能提前完成,团队的目标是"让大版本升级尽可能无聊"
2. 基线要求更新:最低支持 Node 22.22+、React 19.2.7+、Vite 7+,且改为纯 ESM 发布,tsconfig 目标更新至 ES2022
3. Future Flags 转正:v8 移除了多个 future flags,其对应功能现在默认启用,比如中间件、透传请求、Vite Environment API 支持等
4. Remix 走向新方向:Remix v0.x-2.x 的功能已合并回 React Router,Remix 3 将转型为真正的全栈零依赖 JS 框架,与 React Router 并行发展
5. 年度发布节奏:从 v8 开始采用每年一次大版本发布,让升级更可预测、更稳定
6. v6/v7 生命周期:v6 和 Remix v2 正式 EOL,不再接收安全更新;v7 继续接收安全补丁
URL:
https://remix.run/blog/react-router-v8
标签:#前端 #React_Router #Remix #Vite #React19 #SPA_SSR #框架升级
总结:
React Router v8 正式发布,主打"最无聊的大版本升级"理念。v7 引入的 Framework Mode 已成熟,v8 在此基础上将多个 future flags 转正为默认行为,带来 40+ 项改进,包括中间件增强、路由模块拆分、类型安全的 href、Link 遮罩等。破坏性变更极少,升级路径平滑。团队同时宣布采用年度大版本发布节奏,并正式将 React Router v6 和 Remix v2 标记为生命周期结束(EOL)。
文章要点:
1. 升级超省心:v8 的破坏性变更极少,大部分改动在 v7 中就能提前完成,团队的目标是"让大版本升级尽可能无聊"
2. 基线要求更新:最低支持 Node 22.22+、React 19.2.7+、Vite 7+,且改为纯 ESM 发布,tsconfig 目标更新至 ES2022
3. Future Flags 转正:v8 移除了多个 future flags,其对应功能现在默认启用,比如中间件、透传请求、Vite Environment API 支持等
4. Remix 走向新方向:Remix v0.x-2.x 的功能已合并回 React Router,Remix 3 将转型为真正的全栈零依赖 JS 框架,与 React Router 并行发展
5. 年度发布节奏:从 v8 开始采用每年一次大版本发布,让升级更可预测、更稳定
6. v6/v7 生命周期:v6 和 Remix v2 正式 EOL,不再接收安全更新;v7 继续接收安全补丁
URL:
https://remix.run/blog/react-router-v8

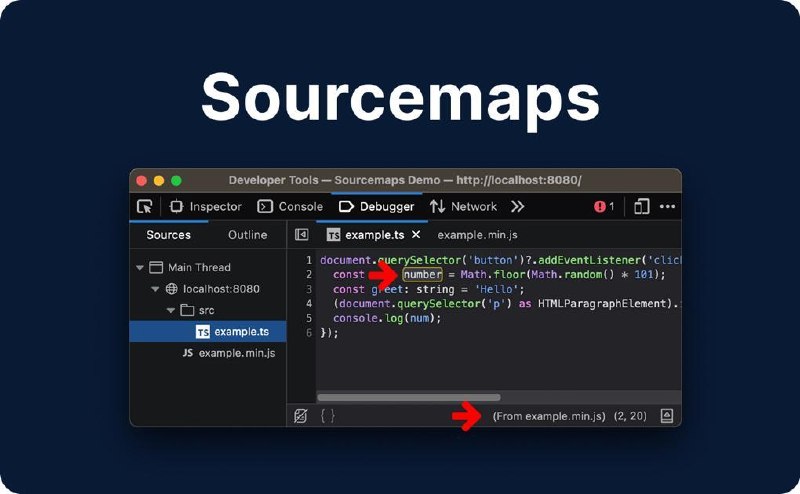
《关于SourceMap你需要知道的一切》
标签:#前端 #SourceMap #Vite #NextJS #Webpack #安全 #CI_CD
总结:SourceMap是前端开发中用于将压缩后的代码映射回原始代码的JSON文件,能极大提升调试体验。但文章重点警示了其安全隐患——默认配置下SourceMap会内联完整源代码,若不慎部署到生产环境,任何人都能通过浏览器或curl获取你的原始代码、目录结构甚至敏感信息。文章以Apple和Anthropic的泄露事件为例,详细说明了如何正确配置构建工具、设置服务器规则以及在CI/CD中自动化检测,防止源代码泄露。
文章要点:
1. SourceMap本质上是一个JSON文件,包含sources(原始文件路径)、names(原始变量名)、mappings(位置映射)和sourcesContent(完整源代码)四个关键字段,能将压缩后的代码精准还原
2. 构建流程通常是TypeScript编译→JS代码→压缩混淆,而SourceMap则反向执行这个流程,让浏览器DevTools能显示原始代码和变量名
3. 最大的安全风险在于sourcesContent默认会内联完整源代码,泄露后不仅暴露目录结构和模块名,还可能泄露API密钥、端点信息和未发布的功能开关
4. Apple在2025年11月因部署SourceMap到生产环境导致App Store前端源码泄露;Anthropic在2026年3月因npm包包含59.8MB的SourceMap文件,导致Claude Code核心代码被永久镜像传播
5. 防护措施包括:构建工具关闭生产环境SourceMap(Vite设sourcemap:false,NextJS设productionBrowserSourceMaps:false)、使用hidden模式仅上传错误追踪平台、服务器对.map请求返回404
6. 建议在CI/CD中添加自动化检查脚本,扫描输出目录中的.map文件,若包含sourcesContent则中断构建,从源头杜绝人为疏忽导致的泄露
URL:https://neciudan.dev/everything-you-need-to-know-about-sourcemaps
标签:#前端 #SourceMap #Vite #NextJS #Webpack #安全 #CI_CD
总结:SourceMap是前端开发中用于将压缩后的代码映射回原始代码的JSON文件,能极大提升调试体验。但文章重点警示了其安全隐患——默认配置下SourceMap会内联完整源代码,若不慎部署到生产环境,任何人都能通过浏览器或curl获取你的原始代码、目录结构甚至敏感信息。文章以Apple和Anthropic的泄露事件为例,详细说明了如何正确配置构建工具、设置服务器规则以及在CI/CD中自动化检测,防止源代码泄露。
文章要点:
1. SourceMap本质上是一个JSON文件,包含sources(原始文件路径)、names(原始变量名)、mappings(位置映射)和sourcesContent(完整源代码)四个关键字段,能将压缩后的代码精准还原
2. 构建流程通常是TypeScript编译→JS代码→压缩混淆,而SourceMap则反向执行这个流程,让浏览器DevTools能显示原始代码和变量名
3. 最大的安全风险在于sourcesContent默认会内联完整源代码,泄露后不仅暴露目录结构和模块名,还可能泄露API密钥、端点信息和未发布的功能开关
4. Apple在2025年11月因部署SourceMap到生产环境导致App Store前端源码泄露;Anthropic在2026年3月因npm包包含59.8MB的SourceMap文件,导致Claude Code核心代码被永久镜像传播
5. 防护措施包括:构建工具关闭生产环境SourceMap(Vite设sourcemap:false,NextJS设productionBrowserSourceMaps:false)、使用hidden模式仅上传错误追踪平台、服务器对.map请求返回404
6. 建议在CI/CD中添加自动化检查脚本,扫描输出目录中的.map文件,若包含sourcesContent则中断构建,从源头杜绝人为疏忽导致的泄露
URL:https://neciudan.dev/everything-you-need-to-know-about-sourcemaps
《TypeScript 每个人都该知道的实用技巧》
标签:#TypeScript #前端开发 #代码质量
总结:
这是一份精心整理的 TypeScript 实战模式合集,涵盖 15 个核心技巧,从基础类型安全到高级类型体操,帮助开发者写出更安全、更可维护、更愉悦的代码。每条建议都配有简洁示例,强调"类型安全不等于运行时安全"这一关键认知,适合各阶段 TS 开发者查漏补缺。
文章要点:
1. 用
2. 让类型推断为你工作:减少不必要的显式注解,避免类型拓宽和维护负担,代码更简洁
3. 用
4. 从值推导类型:用
5. 用可辨识联合建模不可能状态:用
6. 用
7. 配置和常量用
8. 用类型谓语做可复用的收窄:把运行时检查写成
9. 从现有类型构建新类型:掌握
10. 运行时校验外部数据:TypeScript 不验证 API 响应,配合 Zod 等库在边界做运行时校验
11. 多数场景避免
12. 优先使用可推断的泛型:好的 API 设计让用户无需手动传泛型参数,靠上下文自动推断
13. 开启严格编译选项:
14. 学习模板字面量类型:用 ``
15. 类型安全 ≠ 运行时安全:TS 提升正确性,但不替代校验、不保证架构、不消除运行时错误
URL:https://github.com/AllThingsSmitty/typescript-tips-everyone-should-know
标签:#TypeScript #前端开发 #代码质量
总结:
这是一份精心整理的 TypeScript 实战模式合集,涵盖 15 个核心技巧,从基础类型安全到高级类型体操,帮助开发者写出更安全、更可维护、更愉悦的代码。每条建议都配有简洁示例,强调"类型安全不等于运行时安全"这一关键认知,适合各阶段 TS 开发者查漏补缺。
文章要点:
1. 用
unknown 替代 any:强制做类型校验,守住类型安全的第一道防线,防止类型泄漏2. 让类型推断为你工作:减少不必要的显式注解,避免类型拓宽和维护负担,代码更简洁
3. 用
satisfies 代替 as:既验证类型兼容性,又保留具体推断,比强制断言更安全4. 从值推导类型:用
as const + typeof 让运行时和编译时保持同步,告别手动维护两份定义5. 用可辨识联合建模不可能状态:用
status 标签区分状态,比松散的可选属性对象更可靠、更易扩展6. 用
never 做穷尽检查:在 switch 的 default 分支里赋值 never,让未来漏改直接变成编译错误7. 配置和常量用
as const:把对象属性收窄为字面量类型,比如 "dark" 而不是宽泛的 string8. 用类型谓语做可复用的收窄:把运行时检查写成
value is User 形式,让编译器理解你的守卫逻辑9. 从现有类型构建新类型:掌握
Pick、Omit、Partial 等工具类型,用变换思维代替重复定义10. 运行时校验外部数据:TypeScript 不验证 API 响应,配合 Zod 等库在边界做运行时校验
11. 多数场景避免
enum:字面量联合类型通常更易重构、更易序列化、运行时行为更可控12. 优先使用可推断的泛型:好的 API 设计让用户无需手动传泛型参数,靠上下文自动推断
13. 开启严格编译选项:
strict、noUncheckedIndexedAccess 等标志是 TS 真正发挥价值的地方14. 学习模板字面量类型:用 ``
/api/${string} `` 这类模式约束路由、事件名、CSS 工具类等字符串15. 类型安全 ≠ 运行时安全:TS 提升正确性,但不替代校验、不保证架构、不消除运行时错误
URL:https://github.com/AllThingsSmitty/typescript-tips-everyone-should-know
《为什么我放弃Next.js和RSC,回归传统SPA与独立后端》
标签:#前端 #Web开发 #React #NextJS #React_Server_Components #SPA #架构设计 #安全 #TanStack #Hono
总结:
作者回顾了自己从Next.js忠实用户到拥抱App Router/RSC,最终回归传统SPA+独立后端的完整历程。文章深入分析了RSC架构带来的心智负担、序列化开销和安全风险,结合2025-2026年多起严重CVE漏洞,论证了将渲染框架与安全边界解耦的必要性,并分享了当前基于React Router+Vite+Hono的简洁技术栈。
文章要点:
1. Next.js的黄金时代:Pages Router时期心智模型清晰,服务端/客户端边界一目了然,文件路由简单易懂,部署零成本
2. App Router带来的混乱:Server/Client Component区分成为负担,"use client"指令传染性强,开发/构建/生产环境缓存行为不一致,服务端客户端边界变得不可见
3. 安全漏洞敲响警钟:2025年CVE-2025-29927中间件绕过(CVSS 9.1)、2025年底RSC核心包10分满分漏洞CVE-2025-55182、2026年初多起Server Function DoS漏洞,攻击面集中在服务端渲染和反序列化环节
4. TanStack并非避风港:2026年5月TanStack遭遇供应链攻击,42个包被投毒,说明换框架不能免疫风险,减少依赖面才是关键
5. 序列化是根本原因:RSC的"无缝"本质是分布式系统的序列化问题,函数、类实例、错误栈都无法透明穿越边界,反序列化不可信输入成为高危攻击面
6. 当前架构选择:React Router框架模式+Vite纯SPA(仅营销页预渲染)+ Hono独立后端,API通过显式HTTP调用,无RSC负载,无服务端序列化
7. 安全设计原则:认证授权在API层强制执行,前端中间件只做UX跳转,CORS/CSRF/验证码/限流全部在可控的后端实现,与渲染框架彻底解耦
8. 核心收获:架构清晰可指认、无序列化税、前端攻击面趋近于零、后端语言自由选型、依赖更少爆炸半径更小——"无聊"在软件工程里是赞美
URL:https://dev.to/zulikram/why-i-walked-back-from-nextjs-and-rsc-to-a-plain-spa-and-a-separate-backend-4k8p
标签:#前端 #Web开发 #React #NextJS #React_Server_Components #SPA #架构设计 #安全 #TanStack #Hono
总结:
作者回顾了自己从Next.js忠实用户到拥抱App Router/RSC,最终回归传统SPA+独立后端的完整历程。文章深入分析了RSC架构带来的心智负担、序列化开销和安全风险,结合2025-2026年多起严重CVE漏洞,论证了将渲染框架与安全边界解耦的必要性,并分享了当前基于React Router+Vite+Hono的简洁技术栈。
文章要点:
1. Next.js的黄金时代:Pages Router时期心智模型清晰,服务端/客户端边界一目了然,文件路由简单易懂,部署零成本
2. App Router带来的混乱:Server/Client Component区分成为负担,"use client"指令传染性强,开发/构建/生产环境缓存行为不一致,服务端客户端边界变得不可见
3. 安全漏洞敲响警钟:2025年CVE-2025-29927中间件绕过(CVSS 9.1)、2025年底RSC核心包10分满分漏洞CVE-2025-55182、2026年初多起Server Function DoS漏洞,攻击面集中在服务端渲染和反序列化环节
4. TanStack并非避风港:2026年5月TanStack遭遇供应链攻击,42个包被投毒,说明换框架不能免疫风险,减少依赖面才是关键
5. 序列化是根本原因:RSC的"无缝"本质是分布式系统的序列化问题,函数、类实例、错误栈都无法透明穿越边界,反序列化不可信输入成为高危攻击面
6. 当前架构选择:React Router框架模式+Vite纯SPA(仅营销页预渲染)+ Hono独立后端,API通过显式HTTP调用,无RSC负载,无服务端序列化
7. 安全设计原则:认证授权在API层强制执行,前端中间件只做UX跳转,CORS/CSRF/验证码/限流全部在可控的后端实现,与渲染框架彻底解耦
8. 核心收获:架构清晰可指认、无序列化税、前端攻击面趋近于零、后端语言自由选型、依赖更少爆炸半径更小——"无聊"在软件工程里是赞美
URL:https://dev.to/zulikram/why-i-walked-back-from-nextjs-and-rsc-to-a-plain-spa-and-a-separate-backend-4k8p
《Markdown SVG 渲染器:AI 辅助开发的实用小工具》
标签:#前端 #工具 #Markdown #SVG #AI辅助编程 #SimonWillison #WebComponents
总结:
Simon Willison 分享了他用 Claude Opus 4.8 和 GPT-5.5 辅助开发的一个轻量级 Markdown 渲染工具,核心亮点是对 SVG 代码块的特殊处理——不仅能渲染出图像,还提供「渲染图 / 源代码」双标签切换。该工具支持直接粘贴 Markdown、加载远程文件或 GitHub Gist,并用 Fragment URL 记录状态以便分享。整个项目从需求到安全加固完全由 AI 驱动,是「提示驱动开发」的又一实例。
文章要点:
1. 这个工具的诞生源于一个具体场景:Simon 用 LLM CLI 让 Claude Opus 4.8 生成了五组不同思考深度(low 到 max)的「鹈鹕骑自行车」SVG,想找个优雅的方式展示这些 Markdown 日志
2. 核心定制点在于 SVG 围栏代码块(\
3. 支持三种内容输入方式:直接粘贴 Markdown、输入 CORS 兼容的远程 Markdown 文件 URL、或者加载 GitHub Gist 中的第一个文件
4. 用 URL Fragment(#)记录当前加载的文件地址,刷新页面或分享链接时能自动恢复状态,不用依赖后端
5. 安全方面,Simon 后续用 GPT-5.5(Codex xhigh 模式)专门审计并修复了 XSS 漏洞,体现了 AI 辅助开发中「生成 + 安全加固」的两步走思路
6. 整个工具属于 Simon 的「HTML Tools」系列——单文件 HTML+JS+CSS、无构建步骤、托管在 tools.simonwillison.net,目前已积累超过 150 个类似小工具
URL:https://simonwillison.net/2026/May/28/markdown-svg-renderer/
标签:#前端 #工具 #Markdown #SVG #AI辅助编程 #SimonWillison #WebComponents
总结:
Simon Willison 分享了他用 Claude Opus 4.8 和 GPT-5.5 辅助开发的一个轻量级 Markdown 渲染工具,核心亮点是对 SVG 代码块的特殊处理——不仅能渲染出图像,还提供「渲染图 / 源代码」双标签切换。该工具支持直接粘贴 Markdown、加载远程文件或 GitHub Gist,并用 Fragment URL 记录状态以便分享。整个项目从需求到安全加固完全由 AI 驱动,是「提示驱动开发」的又一实例。
文章要点:
1. 这个工具的诞生源于一个具体场景:Simon 用 LLM CLI 让 Claude Opus 4.8 生成了五组不同思考深度(low 到 max)的「鹈鹕骑自行车」SVG,想找个优雅的方式展示这些 Markdown 日志
2. 核心定制点在于 SVG 围栏代码块(\
\\`svg)——普通 Markdown 渲染器只会显示代码,而这个工具会把它变成可交互的 Web Component,默认展示渲染好的 SVG,点击可切换到源码查看3. 支持三种内容输入方式:直接粘贴 Markdown、输入 CORS 兼容的远程 Markdown 文件 URL、或者加载 GitHub Gist 中的第一个文件
4. 用 URL Fragment(#)记录当前加载的文件地址,刷新页面或分享链接时能自动恢复状态,不用依赖后端
5. 安全方面,Simon 后续用 GPT-5.5(Codex xhigh 模式)专门审计并修复了 XSS 漏洞,体现了 AI 辅助开发中「生成 + 安全加固」的两步走思路
6. 整个工具属于 Simon 的「HTML Tools」系列——单文件 HTML+JS+CSS、无构建步骤、托管在 tools.simonwillison.net,目前已积累超过 150 个类似小工具
URL:https://simonwillison.net/2026/May/28/markdown-svg-renderer/
《AI 正在重演前端的"失落十年"吗?》
标签:#前端 #AI编程 #职业发展 #软件工程 # craftsmanship #Bauhaus
总结:
作者将 AI 对编程行业的冲击与前十年 JavaScript 框架对前端的"去技能化"(deskilling)进行类比。框架把浏览器当作编译目标,让通用开发者无需理解 HTML 语义、无障碍、性能等底层知识就能"搞定"前端;AI 编码则进一步将手工写代码的技能消解为"操作半熟练工人使用的技术"。文章认为这降低了从业者议价能力、牺牲了质量,但也承认这是效率提升和抽象层级升高的必然趋势。作者借用 Bauhaus 运动的启示——不是对抗工业化,而是让工匠与工厂协作、以用户为中心重新设计——呼吁在 AI 时代依然需要"懂材料"的人,同时指出商业成功与软件质量本就很少相关,真正的 craft 只会成为更小的切片。
文章要点:
1. "去技能化"正在从特定领域扩散到整个编程行业:框架让前端从专精技能变成通用技能,AI 让编程本身面临同样命运
2. 现代"全栈开发者"往往不是前后端都精通,而是能用框架两边都糊弄的通才,企业因此获得成本节省和人员灵活调配
3. AI 编码是"非确定性抽象"——不像编译器那样稳定,输入或模型的微小变化会导致截然不同的结果,更像是"不会学习的初级工程师"
4. LLM 是 Stack Overflow 复制粘贴的终极进化:让懂行的人更快,让不懂的人也能凑出"能跑"的东西,但抽象泄漏时依然需要有人深入理解并修复
5. 商业成功与软件质量几乎不相关,糟糕的网站对转化率影响有限,且"没人因为选了 React 而被解雇"
6. Bauhaus 运动的启示:不复古也不对抗工业化,而是让设计师回到工坊、与材料共事,最终产出兼顾批量生产和用户体验的设计
7. 前端 craft 不会消失,但会成为更小的切片;就像字体设计不再是全职工作、塑料垃圾泛滥但好工业设计依然存在
8. 快速迭代和 MVP 有其价值,但需要知道自己在验证什么;性能和无障碍等基础如果一开始没做对,后期很难补救
9. AI 只是工具箱里的又一件工具,但 hype 周期内我们会看到丑陋的代码、破碎的沟通和借 AI 之名裁员
10. 作者自己的框架 Mastro 倡导"从简单栈开始、后续再添加功能",反对先上重型框架再试图优化
URL:https://mastrojs.github.io/blog/2026-05-23-is-AI-causing-a-repeat-of-frontends-lost-decade/
标签:#前端 #AI编程 #职业发展 #软件工程 # craftsmanship #Bauhaus
总结:
作者将 AI 对编程行业的冲击与前十年 JavaScript 框架对前端的"去技能化"(deskilling)进行类比。框架把浏览器当作编译目标,让通用开发者无需理解 HTML 语义、无障碍、性能等底层知识就能"搞定"前端;AI 编码则进一步将手工写代码的技能消解为"操作半熟练工人使用的技术"。文章认为这降低了从业者议价能力、牺牲了质量,但也承认这是效率提升和抽象层级升高的必然趋势。作者借用 Bauhaus 运动的启示——不是对抗工业化,而是让工匠与工厂协作、以用户为中心重新设计——呼吁在 AI 时代依然需要"懂材料"的人,同时指出商业成功与软件质量本就很少相关,真正的 craft 只会成为更小的切片。
文章要点:
1. "去技能化"正在从特定领域扩散到整个编程行业:框架让前端从专精技能变成通用技能,AI 让编程本身面临同样命运
2. 现代"全栈开发者"往往不是前后端都精通,而是能用框架两边都糊弄的通才,企业因此获得成本节省和人员灵活调配
3. AI 编码是"非确定性抽象"——不像编译器那样稳定,输入或模型的微小变化会导致截然不同的结果,更像是"不会学习的初级工程师"
4. LLM 是 Stack Overflow 复制粘贴的终极进化:让懂行的人更快,让不懂的人也能凑出"能跑"的东西,但抽象泄漏时依然需要有人深入理解并修复
5. 商业成功与软件质量几乎不相关,糟糕的网站对转化率影响有限,且"没人因为选了 React 而被解雇"
6. Bauhaus 运动的启示:不复古也不对抗工业化,而是让设计师回到工坊、与材料共事,最终产出兼顾批量生产和用户体验的设计
7. 前端 craft 不会消失,但会成为更小的切片;就像字体设计不再是全职工作、塑料垃圾泛滥但好工业设计依然存在
8. 快速迭代和 MVP 有其价值,但需要知道自己在验证什么;性能和无障碍等基础如果一开始没做对,后期很难补救
9. AI 只是工具箱里的又一件工具,但 hype 周期内我们会看到丑陋的代码、破碎的沟通和借 AI 之名裁员
10. 作者自己的框架 Mastro 倡导"从简单栈开始、后续再添加功能",反对先上重型框架再试图优化
URL:https://mastrojs.github.io/blog/2026-05-23-is-AI-causing-a-repeat-of-frontends-lost-decade/
《用 Web Components 构建框架无关的设计系统(实践指南)》
标签:#前端 #WebComponents #设计系统 #Elena #VitePress #CSS #无障碍
总结:
本文是一份超详细的实战教程,手把手教你用 Web Components(通过 Elena 库)和 VitePress 搭建一个框架无关、可发布的设计系统。核心思路是"最低可行层级"——用 web 标准直接写原子组件,避免框架锁定;组件保持"最笨"状态,把复杂业务逻辑留给应用层。文章涵盖 monorepo 结构搭建、Elena 组件脚手架、条件渲染、@scope 样式隔离、CSS 自定义属性主题化,以及通过 JSDoc + Custom Elements Manifest 自动生成 Props 表格的文档工作流。最终产出的是一个可独立发布的组件包 + 可部署的静态文档站。
文章要点:
1. 设计系统从第一天就绑定特定框架(如 React)是"令人费解的"——web 标准组件才是可移植、可组合、经得起时间考验的选择
2. Elena 是"刚好够用的抽象":处理跨框架的 prop/attribute 同步、事件委托等脏活,但不掩盖 web 标准本质
3. 组件应保持"最笨"——被告知显式状态和内容的声明式组件,比内置复杂状态管理的"聪明"组件更健康
4. 设计决策应该在代码中而非 Figma 中完成:现代色彩空间、相对单位、对数排版比例等,设计工具只能模拟浏览器的很小一部分能力
5. 用 @scope 实现样式隔离 + 组件级 CSS 自定义属性作为"最终层 token",既保证封装又有主题化回退
6. JSDoc 注释即文档:Elena 自动生成 custom-elements.json,VitePress 通过 data loader 直接渲染 PropsTable 和 ComponentHeader
7. 文档即测试场:在 VitePress 中实时预览组件,确保跨框架可移植性;开发时 concurrent 运行 watch + docs:dev 实现热更新
8. 条件渲染示例:同一个组件通过 href prop 自动切换 button/a 标签,CTA 链接按钮的常见需求也能语义化实现
URL:https://piccalil.li/blog/framework-agnostic-design-systems-part-1/
标签:#前端 #WebComponents #设计系统 #Elena #VitePress #CSS #无障碍
总结:
本文是一份超详细的实战教程,手把手教你用 Web Components(通过 Elena 库)和 VitePress 搭建一个框架无关、可发布的设计系统。核心思路是"最低可行层级"——用 web 标准直接写原子组件,避免框架锁定;组件保持"最笨"状态,把复杂业务逻辑留给应用层。文章涵盖 monorepo 结构搭建、Elena 组件脚手架、条件渲染、@scope 样式隔离、CSS 自定义属性主题化,以及通过 JSDoc + Custom Elements Manifest 自动生成 Props 表格的文档工作流。最终产出的是一个可独立发布的组件包 + 可部署的静态文档站。
文章要点:
1. 设计系统从第一天就绑定特定框架(如 React)是"令人费解的"——web 标准组件才是可移植、可组合、经得起时间考验的选择
2. Elena 是"刚好够用的抽象":处理跨框架的 prop/attribute 同步、事件委托等脏活,但不掩盖 web 标准本质
3. 组件应保持"最笨"——被告知显式状态和内容的声明式组件,比内置复杂状态管理的"聪明"组件更健康
4. 设计决策应该在代码中而非 Figma 中完成:现代色彩空间、相对单位、对数排版比例等,设计工具只能模拟浏览器的很小一部分能力
5. 用 @scope 实现样式隔离 + 组件级 CSS 自定义属性作为"最终层 token",既保证封装又有主题化回退
6. JSDoc 注释即文档:Elena 自动生成 custom-elements.json,VitePress 通过 data loader 直接渲染 PropsTable 和 ComponentHeader
7. 文档即测试场:在 VitePress 中实时预览组件,确保跨框架可移植性;开发时 concurrent 运行 watch + docs:dev 实现热更新
8. 条件渲染示例:同一个组件通过 href prop 自动切换 button/a 标签,CTA 链接按钮的常见需求也能语义化实现
URL:https://piccalil.li/blog/framework-agnostic-design-systems-part-1/

《别在 div 和 span 上乱加 aria-label》
标签:#前端 #Web无障碍 #ARIA #屏幕阅读器 #HTML语义化
总结:
本文通过实测数据揭示了在 div、span 等 generic 角色元素上使用 aria-label 的严重兼容性问题。ARIA 规范明确禁止为 generic 角色命名,而各屏幕阅读器的表现更是天差地别——有的只读标签、有的只读内容、有的两者都读、有的干脆忽略。这种不一致会让依赖辅助技术的用户获得错误信息,属于典型的"好心办坏事"。作者指出 section 和 popover 是例外,前者加标签会自动升级为 region 地标,后者角色会变为 group。
文章要点:
1. ARIA 规范 5.2.8.6 明确把 generic 角色列入"禁止命名"清单,div 和 span 默认就是这个角色
2. 实测 8 组屏幕阅读器+浏览器组合,对带 aria-label 的 div announcement 结果五花八门:VoiceOver 读"News, group"、TalkBack 只读"News"、JAWS/NVDA 完全忽略标签只读内容
3. 空 div 的测试结果更混乱,有的读"News, empty group"、有的完全静默,无法预测用户会听到什么
4. 这种不可预测性对屏幕阅读器用户是灾难性的——你以为在帮忙标注,实际上可能覆盖了真正有用的内容
5. 例外情况:section 元素加 aria-label 会自动从 generic 升级为 region 地标,这是规范允许的;带 popover 属性的 div 角色会变为 group,加标签也合法
6. 正确做法:需要可访问名称时,优先使用语义化标签(如 button、nav)或显式设置 role,而不是在裸 div 上硬塞 aria-label
URL:https://www.matuzo.at/blog/2026/aria-label-generic-elements
标签:#前端 #Web无障碍 #ARIA #屏幕阅读器 #HTML语义化
总结:
本文通过实测数据揭示了在 div、span 等 generic 角色元素上使用 aria-label 的严重兼容性问题。ARIA 规范明确禁止为 generic 角色命名,而各屏幕阅读器的表现更是天差地别——有的只读标签、有的只读内容、有的两者都读、有的干脆忽略。这种不一致会让依赖辅助技术的用户获得错误信息,属于典型的"好心办坏事"。作者指出 section 和 popover 是例外,前者加标签会自动升级为 region 地标,后者角色会变为 group。
文章要点:
1. ARIA 规范 5.2.8.6 明确把 generic 角色列入"禁止命名"清单,div 和 span 默认就是这个角色
2. 实测 8 组屏幕阅读器+浏览器组合,对带 aria-label 的 div announcement 结果五花八门:VoiceOver 读"News, group"、TalkBack 只读"News"、JAWS/NVDA 完全忽略标签只读内容
3. 空 div 的测试结果更混乱,有的读"News, empty group"、有的完全静默,无法预测用户会听到什么
4. 这种不可预测性对屏幕阅读器用户是灾难性的——你以为在帮忙标注,实际上可能覆盖了真正有用的内容
5. 例外情况:section 元素加 aria-label 会自动从 generic 升级为 region 地标,这是规范允许的;带 popover 属性的 div 角色会变为 group,加标签也合法
6. 正确做法:需要可访问名称时,优先使用语义化标签(如 button、nav)或显式设置 role,而不是在裸 div 上硬塞 aria-label
URL:https://www.matuzo.at/blog/2026/aria-label-generic-elements
《CSS 与 JavaScript 动画性能之争》
标签:#前端 #CSS动画 #JavaScript动画 #WebAnimationsAPI #性能优化 #GSAP #Motion
总结:
本文通过交互式演示拆解了 CSS 与 JS 动画的性能差异真相:CSS Keyframes 和 Transitions 运行在独立线程,主线程阻塞时依然流畅;而传统 JS 动画(如 requestAnimationFrame 循环)与主线程争抢资源,容易卡顿。但 Motion 库通过底层调用 Web Animations API(WAAPI)绕过了这一限制,实现了与 CSS 同级别的流畅度。作者建议优先使用原生 CSS,遇到 CSS 无法覆盖的场景时选择 Motion 等 WAAPI 方案,而非直接上 GSAP 这类纯主线程库。
文章要点:
1. CSS 动画的核心优势不是"计算快",而是运行在独立线程,主线程再忙也不影响动画流畅度
2. 传统 JS 动画(requestAnimationFrame)每帧都在主线程计算,React 重渲染或 fetch 解析时容易掉帧
3. Motion 库(原 Framer Motion)底层使用 Web Animations API,能接入与 CSS 相同的底层动画引擎,主线程阻塞时照样丝滑
4. GSAP 功能极其强大,但坚持在主线程运行,是"能力换性能"的取舍,适合复杂序列动画而非简单过渡
5. 现代 CSS 已经很能打,View Transitions、linear()、Animation Timeline 等新 API 大幅减少了必须上 JS 的场景
6. 选型建议:能用 CSS 就不用库 → CSS 搞不定优先选 Motion/WAAPI → 只有复杂时间线控制才考虑 GSAP
URL:https://www.joshwcomeau.com/animation/css-vs-javascript/
标签:#前端 #CSS动画 #JavaScript动画 #WebAnimationsAPI #性能优化 #GSAP #Motion
总结:
本文通过交互式演示拆解了 CSS 与 JS 动画的性能差异真相:CSS Keyframes 和 Transitions 运行在独立线程,主线程阻塞时依然流畅;而传统 JS 动画(如 requestAnimationFrame 循环)与主线程争抢资源,容易卡顿。但 Motion 库通过底层调用 Web Animations API(WAAPI)绕过了这一限制,实现了与 CSS 同级别的流畅度。作者建议优先使用原生 CSS,遇到 CSS 无法覆盖的场景时选择 Motion 等 WAAPI 方案,而非直接上 GSAP 这类纯主线程库。
文章要点:
1. CSS 动画的核心优势不是"计算快",而是运行在独立线程,主线程再忙也不影响动画流畅度
2. 传统 JS 动画(requestAnimationFrame)每帧都在主线程计算,React 重渲染或 fetch 解析时容易掉帧
3. Motion 库(原 Framer Motion)底层使用 Web Animations API,能接入与 CSS 相同的底层动画引擎,主线程阻塞时照样丝滑
4. GSAP 功能极其强大,但坚持在主线程运行,是"能力换性能"的取舍,适合复杂序列动画而非简单过渡
5. 现代 CSS 已经很能打,View Transitions、linear()、Animation Timeline 等新 API 大幅减少了必须上 JS 的场景
6. 选型建议:能用 CSS 就不用库 → CSS 搞不定优先选 Motion/WAAPI → 只有复杂时间线控制才考虑 GSAP
URL:https://www.joshwcomeau.com/animation/css-vs-javascript/

《TanStack Router 与 Query 的最佳实践》
标签:#前端 #React #TanStackQuery #TanStackRouter #数据获取 #SSR
总结:
本文详解了 TanStack Router 与 TanStack Query 的集成方案,核心思路是将 Router 的 Loader 视为"预取触发器",让 Query 接管全局缓存。通过关闭 Router 内置缓存、在 Loader 中预取 Query、组件中使用 useSuspenseQuery 或 useQuery 的组合策略,实现数据尽早获取、避免请求瀑布,同时兼容 SSR 流式渲染。作者强调始终使用 Query Hooks 而非 useLoaderData 获取数据,以维持自动重取、缓存失效和垃圾回收的正常运作。
文章要点:
1. Router 自带缓存仅限单路由,Query 缓存全局可跨路由共享,更适合多路由共用数据场景
2. 在 Loader 中预取 Query 能让请求在组件渲染前甚至 JS 加载前就开始,配合 prefetch:'intent' 还能实现悬停预加载
3. 关闭 Router 缓存(defaultPreloadStaleTime: 0)避免与 Query 缓存冲突,让 Query 独掌缓存策略
4. 推荐用 useSuspenseQuery 配合 Router 的默认 Error/Pending 边界,组件只需专注"阳光路径"
5. Loader 中不 await 更灵活:useSuspenseQuery 实现阻塞加载,useQuery 实现延迟加载,由组件自主决定
6. SSR 场景下 useSuspenseQuery 更友好,支持流式渐进渲染;useQuery 需在 Loader 中 await 否则服务端无 markup
7. 切勿用 useLoaderData 替代 Query Hooks,否则会导致自动重取、失效刷新和垃圾回收全部失效
8. 将 Loader 视为"事件处理器"——只负责触发预取、不返回数据,是渐进优化性能的好心智模型
URL:https://tkdodo.eu/blog/tan-stack-router-and-query
标签:#前端 #React #TanStackQuery #TanStackRouter #数据获取 #SSR
总结:
本文详解了 TanStack Router 与 TanStack Query 的集成方案,核心思路是将 Router 的 Loader 视为"预取触发器",让 Query 接管全局缓存。通过关闭 Router 内置缓存、在 Loader 中预取 Query、组件中使用 useSuspenseQuery 或 useQuery 的组合策略,实现数据尽早获取、避免请求瀑布,同时兼容 SSR 流式渲染。作者强调始终使用 Query Hooks 而非 useLoaderData 获取数据,以维持自动重取、缓存失效和垃圾回收的正常运作。
文章要点:
1. Router 自带缓存仅限单路由,Query 缓存全局可跨路由共享,更适合多路由共用数据场景
2. 在 Loader 中预取 Query 能让请求在组件渲染前甚至 JS 加载前就开始,配合 prefetch:'intent' 还能实现悬停预加载
3. 关闭 Router 缓存(defaultPreloadStaleTime: 0)避免与 Query 缓存冲突,让 Query 独掌缓存策略
4. 推荐用 useSuspenseQuery 配合 Router 的默认 Error/Pending 边界,组件只需专注"阳光路径"
5. Loader 中不 await 更灵活:useSuspenseQuery 实现阻塞加载,useQuery 实现延迟加载,由组件自主决定
6. SSR 场景下 useSuspenseQuery 更友好,支持流式渐进渲染;useQuery 需在 Loader 中 await 否则服务端无 markup
7. 切勿用 useLoaderData 替代 Query Hooks,否则会导致自动重取、失效刷新和垃圾回收全部失效
8. 将 Loader 视为"事件处理器"——只负责触发预取、不返回数据,是渐进优化性能的好心智模型
URL:https://tkdodo.eu/blog/tan-stack-router-and-query

《Chrome DevTools MCP v1 发布:为 AI 编码代理赋予浏览器调试超能力》
标签:#前端 #AI_Tools #Chrome_DevTools #MCP #Browser_Automation #Performance_Debugging
总结:
Chrome 团队正式发布 DevTools MCP v1,通过 Model Context Protocol 将 Chrome DevTools 的完整调试能力开放给 AI 编码代理。它让 Claude、Cursor、Copilot 等 AI 助手能够实时控制浏览器、抓取性能 trace、分析网络请求、检查控制台日志,甚至处理 1500 万行级别的性能数据,从而把"盲写代码"的 AI 变成能看、能测、能调优的闭环调试器。
文章要点:
1. 告别盲写时代:以前 AI 编码代理只能凭空推理代码,无法看到实际渲染效果。DevTools MCP 直接给 AI 装上"眼睛",让它能截图、查 DOM、读控制台、抓网络请求,基于真实浏览器状态做判断。
2. 40+ 工具全覆盖:从点击、填表、导航等自动化操作,到性能 trace 录制、Lighthouse 审计、内存堆快照、网络请求分析,几乎把 DevTools 面板的能力完整暴露给了 AI。
3. 性能分析是杀手锏:Paul Irish 演示了如何处理 1500 万行 JSON 的复杂性能 trace,MCP 服务器会解析并提炼出关键洞察,让 AI 帮你做原本需要资深性能专家才能完成的初步诊断。
4. 接入零门槛:支持 Claude Code、Cursor、Copilot、Gemini CLI、VS Code 等主流工具,一条 npx 命令即可启动,还能自动连接本地已运行的 Chrome 实例,无需额外配置。
5. 架构扎实可靠:底层基于 Chrome DevTools Protocol 和 Puppeteer,自动化操作自带智能等待,避免 flaky;同时支持 headless 和有头模式,适应不同场景需求。
URL:https://developer.chrome.com/blog/devtools-for-agents-v1
标签:#前端 #AI_Tools #Chrome_DevTools #MCP #Browser_Automation #Performance_Debugging
总结:
Chrome 团队正式发布 DevTools MCP v1,通过 Model Context Protocol 将 Chrome DevTools 的完整调试能力开放给 AI 编码代理。它让 Claude、Cursor、Copilot 等 AI 助手能够实时控制浏览器、抓取性能 trace、分析网络请求、检查控制台日志,甚至处理 1500 万行级别的性能数据,从而把"盲写代码"的 AI 变成能看、能测、能调优的闭环调试器。
文章要点:
1. 告别盲写时代:以前 AI 编码代理只能凭空推理代码,无法看到实际渲染效果。DevTools MCP 直接给 AI 装上"眼睛",让它能截图、查 DOM、读控制台、抓网络请求,基于真实浏览器状态做判断。
2. 40+ 工具全覆盖:从点击、填表、导航等自动化操作,到性能 trace 录制、Lighthouse 审计、内存堆快照、网络请求分析,几乎把 DevTools 面板的能力完整暴露给了 AI。
3. 性能分析是杀手锏:Paul Irish 演示了如何处理 1500 万行 JSON 的复杂性能 trace,MCP 服务器会解析并提炼出关键洞察,让 AI 帮你做原本需要资深性能专家才能完成的初步诊断。
4. 接入零门槛:支持 Claude Code、Cursor、Copilot、Gemini CLI、VS Code 等主流工具,一条 npx 命令即可启动,还能自动连接本地已运行的 Chrome 实例,无需额外配置。
5. 架构扎实可靠:底层基于 Chrome DevTools Protocol 和 Puppeteer,自动化操作自带智能等待,避免 flaky;同时支持 headless 和有头模式,适应不同场景需求。
URL:https://developer.chrome.com/blog/devtools-for-agents-v1

《告别Tailwind,重新学习组织CSS》
标签:#前端 #CSS #TailwindCSS #CSS架构 #响应式设计 #语义化HTML
总结:
文章要点:
1. 作者从Tailwind迁移到语义化HTML+原生CSS,发现Tailwind其实教会了她很多系统性思维(如重置样式、配色、字体层级),现在正把这些系统用原生CSS重新实现。
2. 采用"组件化"CSS架构:每个组件有独立类名和文件,CSS互不覆盖,编辑时只需关注100行左右的局部代码,大幅降低心智负担。
3. 保留Tailwind的实用系统:直接复制preflight重置样式,沿用配色变量和字体尺寸变量,让原生CSS也能像Tailwind一样快速决策"要大一点就用xl"。
4. 响应式设计新思路:减少媒体查询,改用CSS Grid的auto-fit和grid-template-areas实现自适应布局,这是Tailwind难以做到的"奇怪玩法"。
5. 迁移原因:新版Tailwind强依赖构建工具;作者CSS能力提升后想突破Tailwind的限制;受《Tailwind与CSS的女性气质》一文影响,决定认真对待CSS这门技术而非逃避它。
URL:https://jvns.ca/blog/2026/05/15/moving-away-from-tailwind--and-learning-to-structure-my-css-/
标签:#前端 #CSS #TailwindCSS #CSS架构 #响应式设计 #语义化HTML
总结:
文章要点:
1. 作者从Tailwind迁移到语义化HTML+原生CSS,发现Tailwind其实教会了她很多系统性思维(如重置样式、配色、字体层级),现在正把这些系统用原生CSS重新实现。
2. 采用"组件化"CSS架构:每个组件有独立类名和文件,CSS互不覆盖,编辑时只需关注100行左右的局部代码,大幅降低心智负担。
3. 保留Tailwind的实用系统:直接复制preflight重置样式,沿用配色变量和字体尺寸变量,让原生CSS也能像Tailwind一样快速决策"要大一点就用xl"。
4. 响应式设计新思路:减少媒体查询,改用CSS Grid的auto-fit和grid-template-areas实现自适应布局,这是Tailwind难以做到的"奇怪玩法"。
5. 迁移原因:新版Tailwind强依赖构建工具;作者CSS能力提升后想突破Tailwind的限制;受《Tailwind与CSS的女性气质》一文影响,决定认真对待CSS这门技术而非逃避它。
URL:https://jvns.ca/blog/2026/05/15/moving-away-from-tailwind--and-learning-to-structure-my-css-/
《Storybook 10.4 发布》
标签:#前端 #DevTools #Storybook #React #TanStackReact #ReactNative #AIAgent #MCP
总结:
Storybook 10.4 聚焦 AI 辅助开发与团队协作提效。AI Agent 现在能自动完成复杂项目的初始化、Mock 配置、Stories 编写与测试验证;侧边栏新增变更检测过滤器,帮你秒速锁定受代码改动影响的组件;一键分享让非技术成员无需等待 PR 或 CI 就能即时查看工作进度。此外还带来 TanStack React 官方支持、React Native 隔离优化,以及实验性的 React Component Meta 分析器,组件识别率达 100%,热更新速度最高提升 81 倍。
文章要点:
1. AI 全自动配置:只需一句 Prompt,AI Agent 就能分析项目结构、生成 Storybook 配置、编写 MSW Mock 和交互测试,并自动验证渲染效果。已在 Excalidraw、Bluesky 等复杂项目验证可行。
2. 侧边栏变更检测:新增 New、Modified、Related 三种过滤器,帮你秒速锁定代码变更波及的所有 Stories,特别适合 AI 生成代码后的快速审阅。
3. 一键云端分享:点击 Share 按钮即可将当前 Storybook 发布到 Chromatic,设计师和产品经理不用等 PR 或 CI,点开链接就能直接看效果、提反馈。
4. TanStack React 官方支持:全新 @storybook/tanstack-react 包,零配置接入类型安全路由与 Server Functions,由 Storybook 与 TanStack 核心团队联合打造。
5. React Native 隔离升级:新增独立应用入口,通过环境变量自动切换,Storybook 代码与业务代码完全隔离,零配置起步且向后兼容。
6. React Component Meta 实验特性:基于 Volar 和 TS Language Server 的新一代 Docgen,组件检出率 100%,开发模式热更新比旧方案快 43 到 81 倍,为 AI 提供更精准的组件元数据。
URL:https://storybook.js.org/blog/storybook-10-4/
标签:#前端 #DevTools #Storybook #React #TanStackReact #ReactNative #AIAgent #MCP
总结:
Storybook 10.4 聚焦 AI 辅助开发与团队协作提效。AI Agent 现在能自动完成复杂项目的初始化、Mock 配置、Stories 编写与测试验证;侧边栏新增变更检测过滤器,帮你秒速锁定受代码改动影响的组件;一键分享让非技术成员无需等待 PR 或 CI 就能即时查看工作进度。此外还带来 TanStack React 官方支持、React Native 隔离优化,以及实验性的 React Component Meta 分析器,组件识别率达 100%,热更新速度最高提升 81 倍。
文章要点:
1. AI 全自动配置:只需一句 Prompt,AI Agent 就能分析项目结构、生成 Storybook 配置、编写 MSW Mock 和交互测试,并自动验证渲染效果。已在 Excalidraw、Bluesky 等复杂项目验证可行。
2. 侧边栏变更检测:新增 New、Modified、Related 三种过滤器,帮你秒速锁定代码变更波及的所有 Stories,特别适合 AI 生成代码后的快速审阅。
3. 一键云端分享:点击 Share 按钮即可将当前 Storybook 发布到 Chromatic,设计师和产品经理不用等 PR 或 CI,点开链接就能直接看效果、提反馈。
4. TanStack React 官方支持:全新 @storybook/tanstack-react 包,零配置接入类型安全路由与 Server Functions,由 Storybook 与 TanStack 核心团队联合打造。
5. React Native 隔离升级:新增独立应用入口,通过环境变量自动切换,Storybook 代码与业务代码完全隔离,零配置起步且向后兼容。
6. React Component Meta 实验特性:基于 Volar 和 TS Language Server 的新一代 Docgen,组件检出率 100%,开发模式热更新比旧方案快 43 到 81 倍,为 AI 提供更精准的组件元数据。
URL:https://storybook.js.org/blog/storybook-10-4/

《TanStack中的React服务端组件》
标签:#前端 #React_Server_Components #TanStack_Start #NextJs #Bundle_Optimization
总结:
TanStack Start实现了与Next.js截然不同的React服务端组件方案,通过显式API将组件渲染保留在服务端,避免将繁重代码发送至客户端。文章以应用外壳为例,展示RSC如何将客户端Bundle从308KB缩减至203KB,并说明其适合大型非交互式组件树的场景,同时澄清RSC并非数据加载或SSR的替代品,而是针对性的性能优化工具。
文章要点:
1. RSC是只在服务端运行的React组件,可以直接在组件里写await查数据,而且组件代码不会发送到浏览器,不用担心数据库密码暴露给前端
2. TanStack实现RSC的方式特别直白,通过renderServerComponent这类API就能显式声明,作者认为比Next.js的实现更好懂
3. 别误会,RSC不是用来替代数据加载或SSR的,TanStack的loader和原有的服务端渲染已经做得很好了,RSC真正的价值是帮浏览器"减肥"
4. 文章举了个生动的例子:故意引入整个图标库来模拟大型组件树,结果RSC把客户端JS从308KB砍到了203KB,省了不少流量
5. 更妙的是RSC还能接收客户端组件当"插槽"传进来,配合Suspense实现流式渲染,让页面边加载边呈现,体验很丝滑
6. 不过作者也提醒,RSC不是银弹,如果你的组件树不大、依赖不多,用它带来的收益可能微乎其微,得看场景取舍
URL:https://frontendmasters.com/blog/react-server-components-in-tanstack/
标签:#前端 #React_Server_Components #TanStack_Start #NextJs #Bundle_Optimization
总结:
TanStack Start实现了与Next.js截然不同的React服务端组件方案,通过显式API将组件渲染保留在服务端,避免将繁重代码发送至客户端。文章以应用外壳为例,展示RSC如何将客户端Bundle从308KB缩减至203KB,并说明其适合大型非交互式组件树的场景,同时澄清RSC并非数据加载或SSR的替代品,而是针对性的性能优化工具。
文章要点:
1. RSC是只在服务端运行的React组件,可以直接在组件里写await查数据,而且组件代码不会发送到浏览器,不用担心数据库密码暴露给前端
2. TanStack实现RSC的方式特别直白,通过renderServerComponent这类API就能显式声明,作者认为比Next.js的实现更好懂
3. 别误会,RSC不是用来替代数据加载或SSR的,TanStack的loader和原有的服务端渲染已经做得很好了,RSC真正的价值是帮浏览器"减肥"
4. 文章举了个生动的例子:故意引入整个图标库来模拟大型组件树,结果RSC把客户端JS从308KB砍到了203KB,省了不少流量
5. 更妙的是RSC还能接收客户端组件当"插槽"传进来,配合Suspense实现流式渲染,让页面边加载边呈现,体验很丝滑
6. 不过作者也提醒,RSC不是银弹,如果你的组件树不大、依赖不多,用它带来的收益可能微乎其微,得看场景取舍
URL:https://frontendmasters.com/blog/react-server-components-in-tanstack/

《Orval:从OpenAPI规范自动生成类型安全客户端代码》
标签:#前端 #全栈 #OpenAPI #TypeScript #CodeGeneration #ReactQuery #Swagger #APIClient
总结:
Orval 是一个代码生成工具,能读取 OpenAPI v3 或 Swagger v2 规范(支持 yaml 和 json 格式),自动生成带完整 TypeScript 类型签名的客户端代码。它支持 React Query、SWR、Vue Query、Svelte Query、Solid Query、Angular、Hono、Zod、原生 fetch 和 MCP 等多种框架与库,同时还能生成模型、请求函数、Hooks 和 Mock 数据。项目提供在线 Playground 快速体验,开发时使用 Bun 构建,社区活跃且有赞助支持。
文章要点:
1. Orval 的核心能力是从 OpenAPI / Swagger 文档一键生成类型安全的 TS 客户端,告别手写接口代码的繁琐工作
2. 生态支持非常全面,覆盖了 React、Vue、Svelte、Solid、Angular 等主流前端框架,还有 React Query、SWR 等数据获取方案
3. 不只是生成请求函数,还能顺带产出数据模型(Models)、React Hooks、以及用于测试的 Mock 数据,一条龙服务
4. 项目内置了在线 Playground,不用安装就能上手体验,对新手和想快速验证的同学很友好
5. 开发侧使用 Bun 作为包管理工具,测试流程完善,包含单元测试、快照测试和 CLI 验证
URL:https://github.com/orval-labs/orval
标签:#前端 #全栈 #OpenAPI #TypeScript #CodeGeneration #ReactQuery #Swagger #APIClient
总结:
Orval 是一个代码生成工具,能读取 OpenAPI v3 或 Swagger v2 规范(支持 yaml 和 json 格式),自动生成带完整 TypeScript 类型签名的客户端代码。它支持 React Query、SWR、Vue Query、Svelte Query、Solid Query、Angular、Hono、Zod、原生 fetch 和 MCP 等多种框架与库,同时还能生成模型、请求函数、Hooks 和 Mock 数据。项目提供在线 Playground 快速体验,开发时使用 Bun 构建,社区活跃且有赞助支持。
文章要点:
1. Orval 的核心能力是从 OpenAPI / Swagger 文档一键生成类型安全的 TS 客户端,告别手写接口代码的繁琐工作
2. 生态支持非常全面,覆盖了 React、Vue、Svelte、Solid、Angular 等主流前端框架,还有 React Query、SWR 等数据获取方案
3. 不只是生成请求函数,还能顺带产出数据模型(Models)、React Hooks、以及用于测试的 Mock 数据,一条龙服务
4. 项目内置了在线 Playground,不用安装就能上手体验,对新手和想快速验证的同学很友好
5. 开发侧使用 Bun 作为包管理工具,测试流程完善,包含单元测试、快照测试和 CLI 验证
URL:https://github.com/orval-labs/orval