



Now vibe coding, so learning hammer FE ?
《一次被低估的重构如何让内存暴降90%——TanStack_Table_V9内存优化揭秘》
标签:#前端 #TanStackTable #性能优化 #JavaScript #内存管理
总结:
TanStack_Table_V9通过将行、列、单元格和表头对象的方法从实例属性迁移到共享原型上,实现了大型表格场景下最高达90%的内存节省。这一改动让V9能处理1000-1600万行数据(V8仅约150万行即达4GB内存上限),同时保持了动态特性组合的能力,仅带来解构方法调用这一处Breaking_Change。
文章要点:
1. 数据亮眼:处理100万行×8列时,V9比V8节省超2.4GB内存,最高降幅达90.5%,表格承载能力从约150万行跃升至1000-1600万行
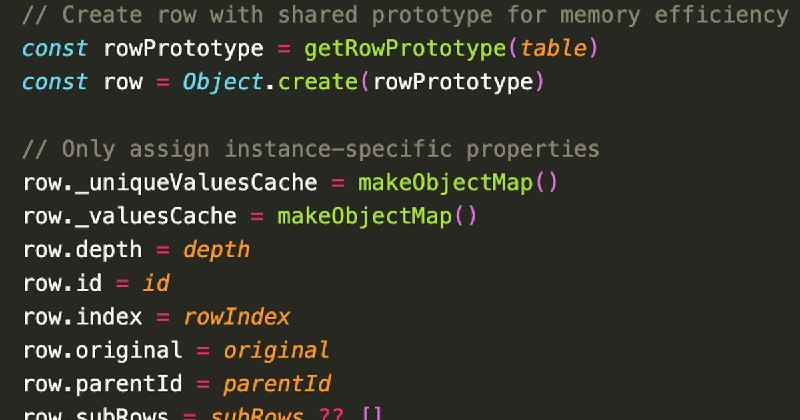
2. 核心手法:用
3. 不用类的智慧:因为TanStack_Table的特性是动态组合的(按需注册排序、筛选、分页等),单继承的Class难以优雅表达"条件式多重继承",手动原型模式更灵活
4. 唯一代价:方法不能再解构调用(如
5. 通用启示:任何需要大规模创建相似对象的库或应用,都可以借鉴这种"共享原型+实例数据分离"的模式来优化内存
URL:https://tanstack.com/blog/tanstack-table-v9-memory-performance
标签:#前端 #TanStackTable #性能优化 #JavaScript #内存管理
总结:
TanStack_Table_V9通过将行、列、单元格和表头对象的方法从实例属性迁移到共享原型上,实现了大型表格场景下最高达90%的内存节省。这一改动让V9能处理1000-1600万行数据(V8仅约150万行即达4GB内存上限),同时保持了动态特性组合的能力,仅带来解构方法调用这一处Breaking_Change。
文章要点:
1. 数据亮眼:处理100万行×8列时,V9比V8节省超2.4GB内存,最高降幅达90.5%,表格承载能力从约150万行跃升至1000-1600万行
2. 核心手法:用
Object.create创建共享原型对象,将方法统一挂载到原型上,实例只保留独有数据,彻底消灭百万级重复函数对象及其闭包作用域3. 不用类的智慧:因为TanStack_Table的特性是动态组合的(按需注册排序、筛选、分页等),单继承的Class难以优雅表达"条件式多重继承",手动原型模式更灵活
4. 唯一代价:方法不能再解构调用(如
const {getValue} = row会丢失this),且Object.keys/{...row}浅拷贝不会包含方法,但直接调用row.getValue()一切正常5. 通用启示:任何需要大规模创建相似对象的库或应用,都可以借鉴这种"共享原型+实例数据分离"的模式来优化内存
URL:https://tanstack.com/blog/tanstack-table-v9-memory-performance
《Node.js流内存泄漏生产级排查手册:五大隐蔽陷阱与五则铁律》
标签:#NodeJS #后端 #流处理 #内存优化 #性能调优
总结:
文章要点:
1. 五大隐蔽泄漏模式:①客户端断开但服务端未感知(legacy pipe() 不处理 premature close)②手动事件解绑是噩梦(async iterator 的 break 自动触发 destroy)③超时只杀响应不杀上游(AbortSignal.timeout 才能全链路终止)④数据库生命周期绑定网络速度(应解耦上游资源与下游传输)⑤pipeline() 异步 destroy 的竞态窗口(catch 里手动补刀 source.destroy)
2. 五则生产铁律:Rule 1 永远用 pipeline() 替代 .pipe(),自动处理错误/完成/背压传播;Rule 2 尊重 .write() 的布尔返回值,并掌握防"Drain Hang"的 AbortController 竞速清理写法;Rule 3 谁创建谁销毁,try/finally + AbortSignal 是标配;Rule 4 用 --max-old-space-size=128 做本地压测,看 writableLength 是否脱离 highWaterMark 失控飙升;Rule 5 写单元测试验证背压,用低 highWaterMark 的慢消费者 mock 检测队列是否暴涨
3. 未来方向:Node.js 正推动"stream-less future",用纯 async generator + pipeline() 替代 legacy Stream API,从 push 模式转为 pull 模式,背压协作变成结构性而非手动检查;Node.js 22 的 stream.compose() 可将多个 generator/流封装为可复用的 Duplex 单元
4. 核心洞察:Node.js 流基于信任系统,破坏信任时不会大声报错,而是静默累积直到崩溃。四行修复代码(检查 write 返回值 + await drain)只是起点,真正的挑战在于理解生产环境中连接断开、超时、慢网络等边界情况
URL:https://frontendmasters.com/blog/the-production-playbook-for-node-js-stream-leaks/
标签:#NodeJS #后端 #流处理 #内存优化 #性能调优
总结:
文章要点:
1. 五大隐蔽泄漏模式:①客户端断开但服务端未感知(legacy pipe() 不处理 premature close)②手动事件解绑是噩梦(async iterator 的 break 自动触发 destroy)③超时只杀响应不杀上游(AbortSignal.timeout 才能全链路终止)④数据库生命周期绑定网络速度(应解耦上游资源与下游传输)⑤pipeline() 异步 destroy 的竞态窗口(catch 里手动补刀 source.destroy)
2. 五则生产铁律:Rule 1 永远用 pipeline() 替代 .pipe(),自动处理错误/完成/背压传播;Rule 2 尊重 .write() 的布尔返回值,并掌握防"Drain Hang"的 AbortController 竞速清理写法;Rule 3 谁创建谁销毁,try/finally + AbortSignal 是标配;Rule 4 用 --max-old-space-size=128 做本地压测,看 writableLength 是否脱离 highWaterMark 失控飙升;Rule 5 写单元测试验证背压,用低 highWaterMark 的慢消费者 mock 检测队列是否暴涨
3. 未来方向:Node.js 正推动"stream-less future",用纯 async generator + pipeline() 替代 legacy Stream API,从 push 模式转为 pull 模式,背压协作变成结构性而非手动检查;Node.js 22 的 stream.compose() 可将多个 generator/流封装为可复用的 Duplex 单元
4. 核心洞察:Node.js 流基于信任系统,破坏信任时不会大声报错,而是静默累积直到崩溃。四行修复代码(检查 write 返回值 + await drain)只是起点,真正的挑战在于理解生产环境中连接断开、超时、慢网络等边界情况
URL:https://frontendmasters.com/blog/the-production-playbook-for-node-js-stream-leaks/

《CSS 与 JavaScript 动画性能之争》
标签:#前端 #CSS动画 #JavaScript动画 #WebAnimationsAPI #性能优化 #GSAP #Motion
总结:
本文通过交互式演示拆解了 CSS 与 JS 动画的性能差异真相:CSS Keyframes 和 Transitions 运行在独立线程,主线程阻塞时依然流畅;而传统 JS 动画(如 requestAnimationFrame 循环)与主线程争抢资源,容易卡顿。但 Motion 库通过底层调用 Web Animations API(WAAPI)绕过了这一限制,实现了与 CSS 同级别的流畅度。作者建议优先使用原生 CSS,遇到 CSS 无法覆盖的场景时选择 Motion 等 WAAPI 方案,而非直接上 GSAP 这类纯主线程库。
文章要点:
1. CSS 动画的核心优势不是"计算快",而是运行在独立线程,主线程再忙也不影响动画流畅度
2. 传统 JS 动画(requestAnimationFrame)每帧都在主线程计算,React 重渲染或 fetch 解析时容易掉帧
3. Motion 库(原 Framer Motion)底层使用 Web Animations API,能接入与 CSS 相同的底层动画引擎,主线程阻塞时照样丝滑
4. GSAP 功能极其强大,但坚持在主线程运行,是"能力换性能"的取舍,适合复杂序列动画而非简单过渡
5. 现代 CSS 已经很能打,View Transitions、linear()、Animation Timeline 等新 API 大幅减少了必须上 JS 的场景
6. 选型建议:能用 CSS 就不用库 → CSS 搞不定优先选 Motion/WAAPI → 只有复杂时间线控制才考虑 GSAP
URL:https://www.joshwcomeau.com/animation/css-vs-javascript/
标签:#前端 #CSS动画 #JavaScript动画 #WebAnimationsAPI #性能优化 #GSAP #Motion
总结:
本文通过交互式演示拆解了 CSS 与 JS 动画的性能差异真相:CSS Keyframes 和 Transitions 运行在独立线程,主线程阻塞时依然流畅;而传统 JS 动画(如 requestAnimationFrame 循环)与主线程争抢资源,容易卡顿。但 Motion 库通过底层调用 Web Animations API(WAAPI)绕过了这一限制,实现了与 CSS 同级别的流畅度。作者建议优先使用原生 CSS,遇到 CSS 无法覆盖的场景时选择 Motion 等 WAAPI 方案,而非直接上 GSAP 这类纯主线程库。
文章要点:
1. CSS 动画的核心优势不是"计算快",而是运行在独立线程,主线程再忙也不影响动画流畅度
2. 传统 JS 动画(requestAnimationFrame)每帧都在主线程计算,React 重渲染或 fetch 解析时容易掉帧
3. Motion 库(原 Framer Motion)底层使用 Web Animations API,能接入与 CSS 相同的底层动画引擎,主线程阻塞时照样丝滑
4. GSAP 功能极其强大,但坚持在主线程运行,是"能力换性能"的取舍,适合复杂序列动画而非简单过渡
5. 现代 CSS 已经很能打,View Transitions、linear()、Animation Timeline 等新 API 大幅减少了必须上 JS 的场景
6. 选型建议:能用 CSS 就不用库 → CSS 搞不定优先选 Motion/WAAPI → 只有复杂时间线控制才考虑 GSAP
URL:https://www.joshwcomeau.com/animation/css-vs-javascript/

《Python 3.15的JIT编译器重回正轨》
标签:#Python #JIT #CPython #性能优化 #Faster_CPython #编译器 #开源社区
总结:
Python 3.15的JIT编译器开发取得突破性进展,在失去主要赞助商后通过社区协作成功实现性能目标。目前macOS AArch64平台比解释器快11-12%,Linux x86_64快5-6%,提前完成预定目标。文章强调了团队建设、任务分解和幸运的技术决策(如追踪记录解释器和引用计数消除)对项目成功的关键作用。
文章要点:
- **性能目标提前达成**:Python 3.15的JIT在macOS AArch64上比尾调用解释器快11-12%,在Linux x86_64上比标准解释器快5-6%,提前一年多完成目标
- **从困境中重生**:Faster CPython团队2025年失去主要赞助商后,通过社区托管模式维持开发,作者曾怀疑JIT项目能否成功
- **降低"巴士因子"风险**:团队计划在JIT的前端(区域选择器)、中端(优化器)、后端(代码生成器)各配备2名活跃维护者,目前中端已有4名贡献者
- **任务分解吸引新人**:将复杂优化问题拆分为简单任务(如"优化单条指令"),提供详细可操作的指导,让无JIT经验的C程序员也能参与,共11人参与核心重构
- **关键技术决策**:Brandt建议改用追踪式前端,Mark建议双分派表机制,意外地将追踪解释器性能从慢6%提升到快1.x%,并将JIT代码覆盖率提升50%
- **引用计数消除优化**:消除每条Python指令的分支操作,这一优化易于并行化且适合教学,是3.15版本的主要优化方向
- **基础设施支撑**:Savannah Ostrowski一人搭建了等效于整个基础设施团队的CI系统,每日性能测试帮助快速发现回归问题
文章URL:
https://fidget-spinner.github.io/posts/jit-on-track.html
标签:#Python #JIT #CPython #性能优化 #Faster_CPython #编译器 #开源社区
总结:
Python 3.15的JIT编译器开发取得突破性进展,在失去主要赞助商后通过社区协作成功实现性能目标。目前macOS AArch64平台比解释器快11-12%,Linux x86_64快5-6%,提前完成预定目标。文章强调了团队建设、任务分解和幸运的技术决策(如追踪记录解释器和引用计数消除)对项目成功的关键作用。
文章要点:
- **性能目标提前达成**:Python 3.15的JIT在macOS AArch64上比尾调用解释器快11-12%,在Linux x86_64上比标准解释器快5-6%,提前一年多完成目标
- **从困境中重生**:Faster CPython团队2025年失去主要赞助商后,通过社区托管模式维持开发,作者曾怀疑JIT项目能否成功
- **降低"巴士因子"风险**:团队计划在JIT的前端(区域选择器)、中端(优化器)、后端(代码生成器)各配备2名活跃维护者,目前中端已有4名贡献者
- **任务分解吸引新人**:将复杂优化问题拆分为简单任务(如"优化单条指令"),提供详细可操作的指导,让无JIT经验的C程序员也能参与,共11人参与核心重构
- **关键技术决策**:Brandt建议改用追踪式前端,Mark建议双分派表机制,意外地将追踪解释器性能从慢6%提升到快1.x%,并将JIT代码覆盖率提升50%
- **引用计数消除优化**:消除每条Python指令的分支操作,这一优化易于并行化且适合教学,是3.15版本的主要优化方向
- **基础设施支撑**:Savannah Ostrowski一人搭建了等效于整个基础设施团队的CI系统,每日性能测试帮助快速发现回归问题
文章URL:
https://fidget-spinner.github.io/posts/jit-on-track.html
《关于协作编辑的谎言(第二部分):为什么我们不用Yjs》
标签:#前端 #ProseMirror #CRDT #协作编辑 #性能优化 #Yjs #实时协作
总结:
本文是Moment.dev团队关于协作编辑算法分析的第二部分,作者详细阐述了为何在生产环境中放弃Yjs而选择基于ProseMirror-collab的简单方案。文章指出Yjs存在严重的性能问题(每次协作编辑会销毁重建整个文档)、与文档Schema冲突、权限控制困难、调试困难以及墓碑数据占用内存等问题。作者认为,除非真正需要无主节点的P2P架构,否则40行代码的"简单方案"在性能、可维护性和开发体验上都优于复杂的CRDT实现。
文章要点:
- Yjs存在严重性能缺陷:每次协作编辑会销毁并重建整个文档,导致60fps目标难以达成,影响NodeView、插件状态、撤销功能和光标位置管理
- 简单方案仅需40行代码:使用prosemirror-collab库,通过单一权威节点管理文档版本和事务,支持乐观更新、离线编辑和网络中断恢复
- Yjs与文档Schema冲突:在无主节点架构下难以验证事务有效性,可能导致数据永久丢失,升级时尤其危险
- 权限控制复杂化:需要将Yjs的XML更新预测转换为ProseMirror事务来判断权限,实现难度大
- 墓碑数据问题:Yjs需保留删除标记,导致内存持续增长或数据丢失风险,而简单方案通过数据库存储步骤即可解决
- 调试困难:CRDT仅保证最终一致性,难以区分暂时分歧与真正错误,调试工具受限
- 核心观点:技术选型应从最终用户体验出发,而非算法本身;如无P2P刚需,简单方案在各方面均优于CRDT
文章URL:https://www.moment.dev/blog/lies-i-was-told-pt-2
标签:#前端 #ProseMirror #CRDT #协作编辑 #性能优化 #Yjs #实时协作
总结:
本文是Moment.dev团队关于协作编辑算法分析的第二部分,作者详细阐述了为何在生产环境中放弃Yjs而选择基于ProseMirror-collab的简单方案。文章指出Yjs存在严重的性能问题(每次协作编辑会销毁重建整个文档)、与文档Schema冲突、权限控制困难、调试困难以及墓碑数据占用内存等问题。作者认为,除非真正需要无主节点的P2P架构,否则40行代码的"简单方案"在性能、可维护性和开发体验上都优于复杂的CRDT实现。
文章要点:
- Yjs存在严重性能缺陷:每次协作编辑会销毁并重建整个文档,导致60fps目标难以达成,影响NodeView、插件状态、撤销功能和光标位置管理
- 简单方案仅需40行代码:使用prosemirror-collab库,通过单一权威节点管理文档版本和事务,支持乐观更新、离线编辑和网络中断恢复
- Yjs与文档Schema冲突:在无主节点架构下难以验证事务有效性,可能导致数据永久丢失,升级时尤其危险
- 权限控制复杂化:需要将Yjs的XML更新预测转换为ProseMirror事务来判断权限,实现难度大
- 墓碑数据问题:Yjs需保留删除标记,导致内存持续增长或数据丢失风险,而简单方案通过数据库存储步骤即可解决
- 调试困难:CRDT仅保证最终一致性,难以区分暂时分歧与真正错误,调试工具受限
- 核心观点:技术选型应从最终用户体验出发,而非算法本身;如无P2P刚需,简单方案在各方面均优于CRDT
文章URL:https://www.moment.dev/blog/lies-i-was-told-pt-2

《前端内存泄漏:500仓库静态分析与五场景基准测试实证研究》
标签:#前端 #内存泄漏 #性能优化 #React #Vue #Angular #useEffect #静态分析 #基准测试
总结(一段话概括)
该研究对500个开源前端仓库(React/Vue/Angular)进行AST静态分析,发现86%的代码库存在至少一处缺失清理的内存泄漏模式,共识别55,864个潜在泄漏点,其中定时器清理缺失占比最高(43.9%)。通过五个控制变量的基准测试(各50轮×100次挂载循环)证实:每处未清理模式每次挂载/卸载循环平均泄漏约8KB内存,呈线性累积趋势;而正确清理的版本内存增长接近零(约2KB总计)。研究揭示了内存泄漏在前端生产代码中的普遍性及其对长会话应用(如仪表板、视频会议)的性能威胁,并提供了针对性的修复方案。
文章要点:
- 高普遍性:扫描714,217个文件发现55,864处潜在泄漏,430/500个仓库(86%)存在至少一处缺失清理模式,涵盖Kibana、Next.js等知名项目
- 主要泄漏源:定时器未清理(43.9%,22,384处)居首,其次是事件监听器(19.0%)、订阅未取消(13.9%)、useEffect无清理函数(9.3%)
- 统一泄漏成本:五个跨框架场景(React useEffect、Vue onMounted、Angular subscribe、Vue watch、RAF)均显示每循环约8KB线性内存增长,标准差极小(±0.6–37KB),而正确清理版本仅2-3KB噪声基线
- 统计显著性:效应量Cohen's d > 200(BAD与GOOD分布零重叠),p < 0.001,统计功效超99.99%,证实清理缺失是内存占用的主导变量
- 框架差异:React占发现总量62.3%(样本加权),Vue的
- 高危上下文:组件生命周期代码(32.9%)和事件绑定(24.5%)是高发区,因路由切换、标签页切换会频繁触发挂载/卸载
- 实际影响:单泄漏模式200次导航累积1.6MB,多模式叠加可达8MB/会话,足以触发移动端浏览器(iOS Safari 80-120MB阈值)杀标签页
- 修复成本低:92.3%的修复仅需单行代码(返回清理函数、存储stop handle、takeUntil模式),ROI极高
- 工具链缺口:现有ESLint规则(如react-hooks/exhaustive-deps)无法检测清理函数缺失,需借助AST级静态分析或生产环境堆内存监控
文章URL
https://stackinsight.dev/blog/memory-leak-empirical-study/
标签:#前端 #内存泄漏 #性能优化 #React #Vue #Angular #useEffect #静态分析 #基准测试
总结(一段话概括)
该研究对500个开源前端仓库(React/Vue/Angular)进行AST静态分析,发现86%的代码库存在至少一处缺失清理的内存泄漏模式,共识别55,864个潜在泄漏点,其中定时器清理缺失占比最高(43.9%)。通过五个控制变量的基准测试(各50轮×100次挂载循环)证实:每处未清理模式每次挂载/卸载循环平均泄漏约8KB内存,呈线性累积趋势;而正确清理的版本内存增长接近零(约2KB总计)。研究揭示了内存泄漏在前端生产代码中的普遍性及其对长会话应用(如仪表板、视频会议)的性能威胁,并提供了针对性的修复方案。
文章要点:
- 高普遍性:扫描714,217个文件发现55,864处潜在泄漏,430/500个仓库(86%)存在至少一处缺失清理模式,涵盖Kibana、Next.js等知名项目
- 主要泄漏源:定时器未清理(43.9%,22,384处)居首,其次是事件监听器(19.0%)、订阅未取消(13.9%)、useEffect无清理函数(9.3%)
- 统一泄漏成本:五个跨框架场景(React useEffect、Vue onMounted、Angular subscribe、Vue watch、RAF)均显示每循环约8KB线性内存增长,标准差极小(±0.6–37KB),而正确清理版本仅2-3KB噪声基线
- 统计显著性:效应量Cohen's d > 200(BAD与GOOD分布零重叠),p < 0.001,统计功效超99.99%,证实清理缺失是内存占用的主导变量
- 框架差异:React占发现总量62.3%(样本加权),Vue的
watch未存储stop handle(3,989处)和Angular的.subscribe()未取消(5,327处)均为高危模式- 高危上下文:组件生命周期代码(32.9%)和事件绑定(24.5%)是高发区,因路由切换、标签页切换会频繁触发挂载/卸载
- 实际影响:单泄漏模式200次导航累积1.6MB,多模式叠加可达8MB/会话,足以触发移动端浏览器(iOS Safari 80-120MB阈值)杀标签页
- 修复成本低:92.3%的修复仅需单行代码(返回清理函数、存储stop handle、takeUntil模式),ROI极高
- 工具链缺口:现有ESLint规则(如react-hooks/exhaustive-deps)无法检测清理函数缺失,需借助AST级静态分析或生产环境堆内存监控
文章URL
https://stackinsight.dev/blog/memory-leak-empirical-study/

《理解 React Fiber 存在的意义》
标签:#前端 #React #React_Fiber #性能优化 #并发渲染 #Virtual_DOM
总结(一段话概括)
React Fiber 是 React 16 对核心协调算法的彻底重写,旨在解决 React 15 中 Stack Reconciler 同步递归更新导致的主线程阻塞问题。通过将组件树重构为链表结构的 Fiber 节点,React 实现了可中断的异步更新、任务优先级调度和时间切片机制,使高优先级任务(如用户输入)能插队执行,避免页面卡顿,并为 Concurrent Mode、Suspense 等现代特性奠定基础。
文章要点:
- React 15 的瓶颈:Stack Reconciler 采用递归遍历,更新一旦开始无法中断,复杂组件树会导致主线程长时间阻塞,造成掉帧和交互卡顿
- Fiber 的本质:将同步更新改为可中断的异步更新,每个 Fiber 节点是一个执行单元,通过
- 时间切片(Time Slicing):利用
- 优先级调度:引入 Lanes 机制,区分 Immediate(最高)、UserBlocking、Normal、Low、Idle 五级优先级,确保紧急更新优先处理
- 双缓冲机制:维护
- Phase 分离:将更新分为 Render 阶段(可中断,构建 Fiber 树)和 Commit 阶段(不可中断,同步执行 DOM 操作),支持错误边界(Error Boundaries)捕获
- 架构演进:从 React 15 的两层(Reconciler + Renderer)增至 React 16+ 的三层(Scheduler + Reconciler + Renderer),调度器负责任务分配和中断控制
文章URL:https://inside-react.vercel.app/blog/understanding-why-react-fiber-exists
标签:#前端 #React #React_Fiber #性能优化 #并发渲染 #Virtual_DOM
总结(一段话概括)
React Fiber 是 React 16 对核心协调算法的彻底重写,旨在解决 React 15 中 Stack Reconciler 同步递归更新导致的主线程阻塞问题。通过将组件树重构为链表结构的 Fiber 节点,React 实现了可中断的异步更新、任务优先级调度和时间切片机制,使高优先级任务(如用户输入)能插队执行,避免页面卡顿,并为 Concurrent Mode、Suspense 等现代特性奠定基础。
文章要点:
- React 15 的瓶颈:Stack Reconciler 采用递归遍历,更新一旦开始无法中断,复杂组件树会导致主线程长时间阻塞,造成掉帧和交互卡顿
- Fiber 的本质:将同步更新改为可中断的异步更新,每个 Fiber 节点是一个执行单元,通过
child、sibling、return 指针形成链表树,取代递归调用栈- 时间切片(Time Slicing):利用
requestIdleCallback polyfill(基于 MessageChannel),在浏览器每帧(16.6ms)中预留时间(默认 5ms)给 React,超时即让出主线程控制权- 优先级调度:引入 Lanes 机制,区分 Immediate(最高)、UserBlocking、Normal、Low、Idle 五级优先级,确保紧急更新优先处理
- 双缓冲机制:维护
current Fiber 和 workInProgress Fiber 两棵树,通过 alternate 指针关联,渲染完成后直接切换指针指向,避免重复创建对象- Phase 分离:将更新分为 Render 阶段(可中断,构建 Fiber 树)和 Commit 阶段(不可中断,同步执行 DOM 操作),支持错误边界(Error Boundaries)捕获
- 架构演进:从 React 15 的两层(Reconciler + Renderer)增至 React 16+ 的三层(Scheduler + Reconciler + Renderer),调度器负责任务分配和中断控制
文章URL:https://inside-react.vercel.app/blog/understanding-why-react-fiber-exists

《我们将 Node.js 内存占用减少了一半》
标签:#后端 #Node.js #V8 #性能优化 #内存管理 #Docker
本文介绍了通过启用 V8 引擎的指针压缩(Pointer Compression)技术,在不修改代码的情况下将 Node.js 应用内存占用减少约 50%,且仅带来 2-4% 的平均延迟开销,同时显著降低 P99 延迟。Cloudflare 与 Igalia 合作解决了历史性的"4GB 内存笼"限制,使每个 Worker 线程拥有独立的 4GB 压缩内存空间。
文章要点:
- 技术原理:指针压缩将 64 位指针转为 32 位偏移量,使每个指针从 8 字节减至 4 字节,内存占用减半,代价是每次堆访问需额外的加减法运算
- 历史障碍:此前 Node.js 未默认启用是因所有 Worker 线程共享单一 4GB 内存空间,2024 年 Cloudflare 与 Igalia 合作推出 IsolateGroups 功能,使每个 V8 实例拥有独立的 4GB 压缩内存笼
- 实验结果:在 Next.js 电商应用基准测试中,指针压缩实现内存减半(2GB→1GB),平均延迟仅增加 2.5-4.2%,但 P99 延迟降低 7-43%,最大延迟降低 6-38%,因更小的堆减少了 GC 暂停时间
- 业务价值:可显著降低 Kubernetes 集群成本、提升多租户 SaaS 密度、支持边缘计算部署、增加 WebSocket 并发连接数
- 兼容性限制:每个 V8 实例仍受 4GB 堆内存限制;使用旧版 NAN 的原生插件不兼容,但 Node-API 插件不受影响
- 使用方式:通过
链接:https://blog.platformatic.dev/we-cut-nodejs-memory-in-half
标签:#后端 #Node.js #V8 #性能优化 #内存管理 #Docker
本文介绍了通过启用 V8 引擎的指针压缩(Pointer Compression)技术,在不修改代码的情况下将 Node.js 应用内存占用减少约 50%,且仅带来 2-4% 的平均延迟开销,同时显著降低 P99 延迟。Cloudflare 与 Igalia 合作解决了历史性的"4GB 内存笼"限制,使每个 Worker 线程拥有独立的 4GB 压缩内存空间。
文章要点:
- 技术原理:指针压缩将 64 位指针转为 32 位偏移量,使每个指针从 8 字节减至 4 字节,内存占用减半,代价是每次堆访问需额外的加减法运算
- 历史障碍:此前 Node.js 未默认启用是因所有 Worker 线程共享单一 4GB 内存空间,2024 年 Cloudflare 与 Igalia 合作推出 IsolateGroups 功能,使每个 V8 实例拥有独立的 4GB 压缩内存笼
- 实验结果:在 Next.js 电商应用基准测试中,指针压缩实现内存减半(2GB→1GB),平均延迟仅增加 2.5-4.2%,但 P99 延迟降低 7-43%,最大延迟降低 6-38%,因更小的堆减少了 GC 暂停时间
- 业务价值:可显著降低 Kubernetes 集群成本、提升多租户 SaaS 密度、支持边缘计算部署、增加 WebSocket 并发连接数
- 兼容性限制:每个 V8 实例仍受 4GB 堆内存限制;使用旧版 NAN 的原生插件不兼容,但 Node-API 插件不受影响
- 使用方式:通过
platformatic/node-caged Docker 镜像一键替换官方 Node.js 镜像即可启用链接:https://blog.platformatic.dev/we-cut-nodejs-memory-in-half
十亿行数据的虚拟滚动技术——HighTable 的五大实现方案
标签:#前端 #React #虚拟滚动 #性能优化 #大数据表格 #HighTable #DOM优化
总结:本文介绍了 HighTable 组件实现十亿级数据表格渲染的五大核心技术:懒加载仅获取可视区域数据、表格切片只渲染可见行、无限像素技术通过缩放滚动条突破浏览器高度限制、双模式滚动实现全局跳转与本地精确定位、两步随机访问分离垂直与水平滚动逻辑。这些方案完全基于原生 HTML 与 CSS,无需 Canvas 或自定义滚动条即可在浏览器中流畅处理海量数据。
文章要点:
- 技术1:懒加载:仅加载可视区域单元格数据,通过 DataFrame 接口异步获取并缓存数据,将 1TB 数据缩减为仅需加载约 3KB 的可见区域
- 技术2:表格切片:引入 Canvas 层作为定位参考,仅渲染可见行(约 30 行)而非全部十亿行,将 DOM 元素数量控制在恒定范围内
- 技术3:无限像素:设置 Canvas 最大高度(800 万像素),超过阈值时通过 downscaleFactor 缩放滚动条分辨率,突破浏览器元素高度限制(Firefox 约 1700 万像素)
- 技术4:像素级精确滚动:实现本地滚动(小幅度移动保持行连续性)与全局滚动(大幅度跳转)双模式,通过 globalAnchor 和 localOffset 状态管理,确保 2 万亿行内可达任意像素
- 技术5:两步随机访问:解耦垂直与水平滚动逻辑,先计算目标位置并垂直滚动,渲染完成后再处理水平定位与焦点设置,支持键盘导航和程序化跳转至任意单元格
链接:https://rednegra.net/blog/20260212-virtual-scroll/
标签:#前端 #React #虚拟滚动 #性能优化 #大数据表格 #HighTable #DOM优化
总结:本文介绍了 HighTable 组件实现十亿级数据表格渲染的五大核心技术:懒加载仅获取可视区域数据、表格切片只渲染可见行、无限像素技术通过缩放滚动条突破浏览器高度限制、双模式滚动实现全局跳转与本地精确定位、两步随机访问分离垂直与水平滚动逻辑。这些方案完全基于原生 HTML 与 CSS,无需 Canvas 或自定义滚动条即可在浏览器中流畅处理海量数据。
文章要点:
- 技术1:懒加载:仅加载可视区域单元格数据,通过 DataFrame 接口异步获取并缓存数据,将 1TB 数据缩减为仅需加载约 3KB 的可见区域
- 技术2:表格切片:引入 Canvas 层作为定位参考,仅渲染可见行(约 30 行)而非全部十亿行,将 DOM 元素数量控制在恒定范围内
- 技术3:无限像素:设置 Canvas 最大高度(800 万像素),超过阈值时通过 downscaleFactor 缩放滚动条分辨率,突破浏览器元素高度限制(Firefox 约 1700 万像素)
- 技术4:像素级精确滚动:实现本地滚动(小幅度移动保持行连续性)与全局滚动(大幅度跳转)双模式,通过 globalAnchor 和 localOffset 状态管理,确保 2 万亿行内可达任意像素
- 技术5:两步随机访问:解耦垂直与水平滚动逻辑,先计算目标位置并垂直滚动,渲染完成后再处理水平定位与焦点设置,支持键盘导航和程序化跳转至任意单元格
链接:https://rednegra.net/blog/20260212-virtual-scroll/